join the Figure Friday session on December 20, at noon Eastern Time, to showcase your creation and receive feedback from the community.
Did you know that Palm kernel oil saw a 27% increase in price between October and November of 2024?
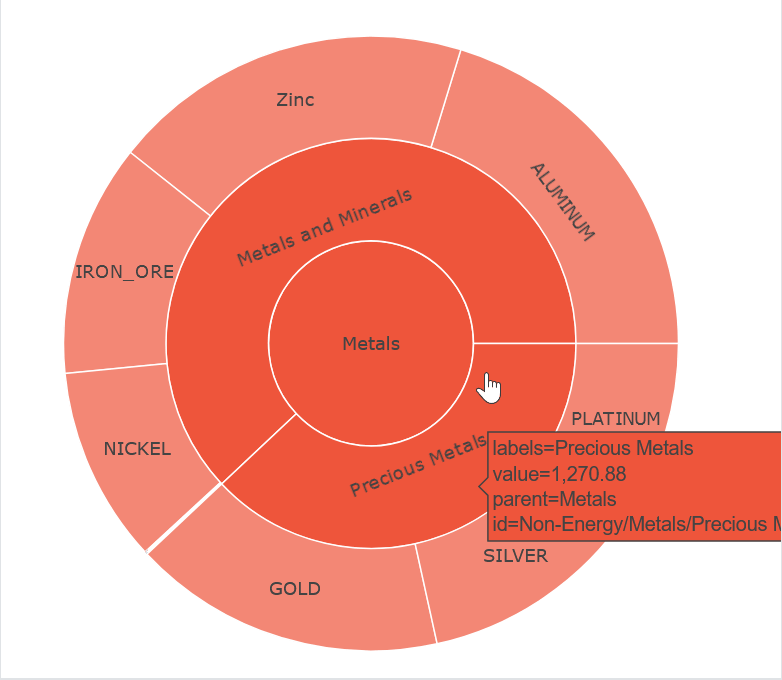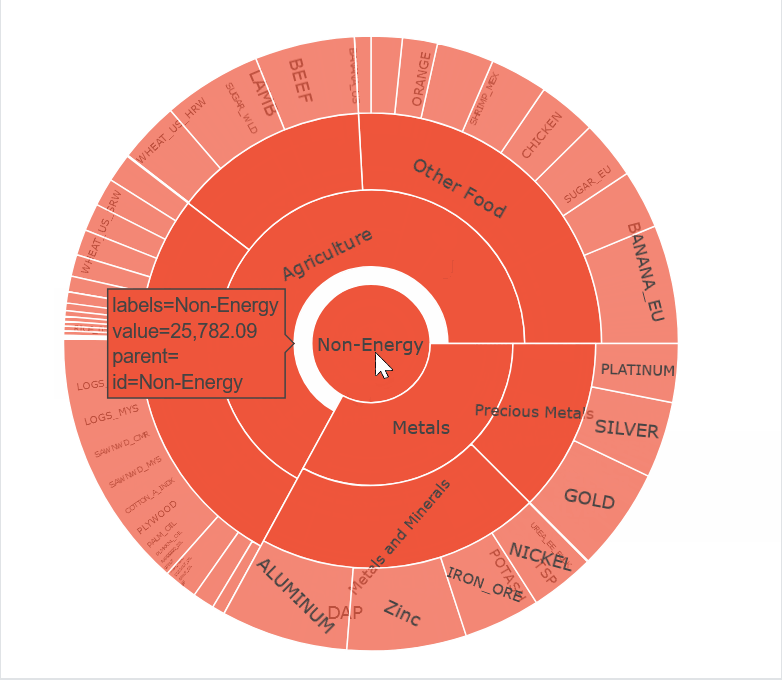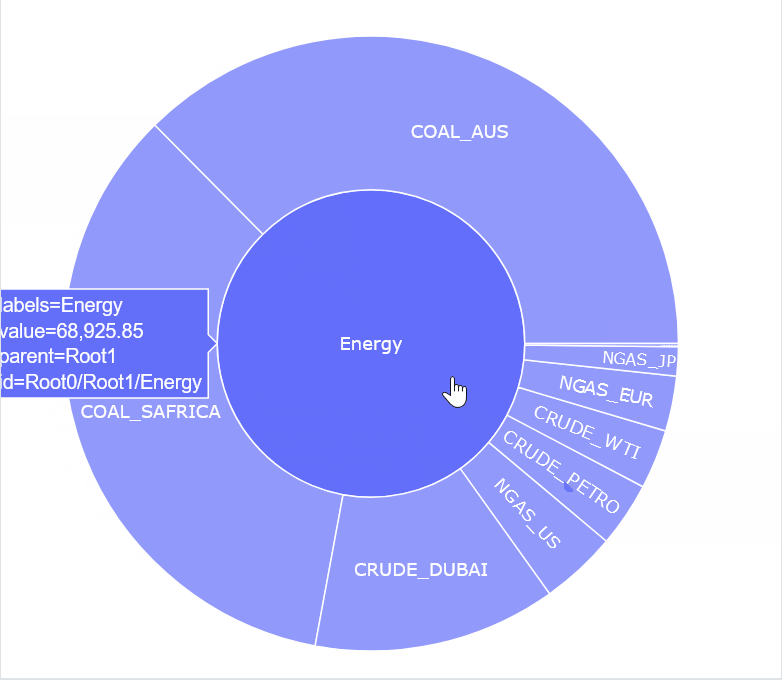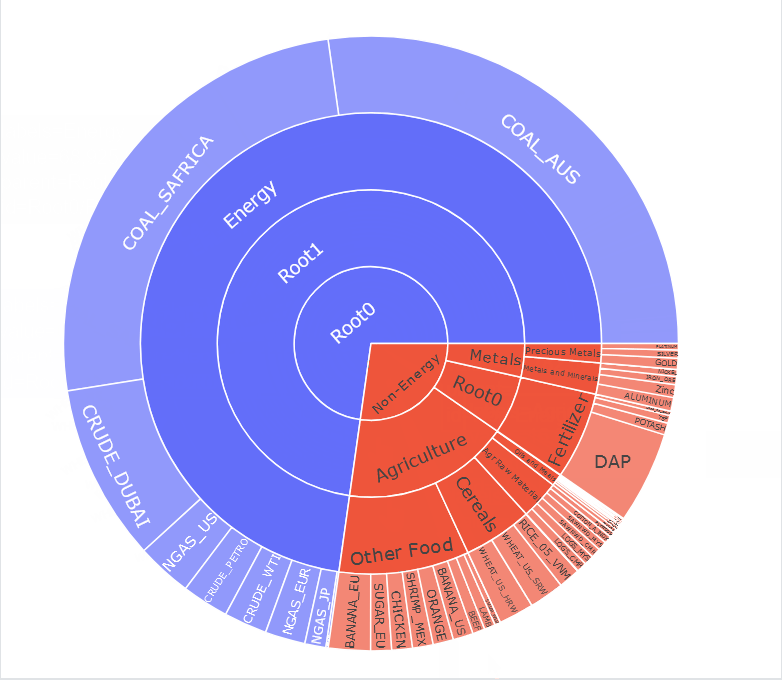
In this week’s Figure-Friday we’ll look at Commodity Markets and their monthly prices, provided by the World Bank Group.
In case you’re interested in more info such as monthly indices for particular sectors (energy, agriculture, etc.) or a data description, simply download this Worldbank excel sheet and view the other 3 sheets/tabs: Monthly Indices, Description, and Index Weights.
Things to consider:
- can you improve the sample figure below (bar plot)?
- would a different figure tell the data story better?
- can you create a Dash app instead?
Sample figure:

Code for sample figure:
import pandas as pd
import plotly.graph_objects as go
df = pd.read_csv("https://raw.githubusercontent.com/plotly/Figure-Friday/refs/heads/main/2024/week-50/CMO-Historical-Data-Monthly.csv")
df = df.drop([0, 1]) # drop sub headers
df.rename(columns={'Unnamed: 0': 'Time'}, inplace=True)
df['Time'] = pd.to_datetime(df['Time'], format='%YM%m')
# Convert all columns (except 'Time') to numeric
df.iloc[:, 1:] = df.iloc[:, 1:].apply(pd.to_numeric, errors='coerce')
# Recalculate values for October and November 2024 because we plan to find percentage changes between those months
oct_values = df[df['Time'] == '2024-10-01'].iloc[0, 1:]
nov_values = df[df['Time'] == '2024-11-01'].iloc[0, 1:]
# Calculate percentage change between November and October 2024
percent_change = ((nov_values - oct_values) / oct_values) * 100
# Prepare data for the Plotly bar chart
commodities = percent_change.index.tolist()
positive_changes = percent_change[percent_change > 0].values
negative_changes = -percent_change[percent_change < 0].values
fig = go.Figure()
# Add bars for percentage changes (positive and negative on the same axis)
fig.add_trace(go.Bar(
x=percent_change,
y=commodities,
orientation='h',
marker_color=percent_change.apply(lambda x: 'green' if x > 0 else 'red'),
name='Percent Change'
))
fig.update_layout(
title='Percent Change in Commodities (Oct 2024 vs Nov 2024)',
barmode='relative',
template='plotly_white',
xaxis=dict(ticksuffix='%', zeroline=True, zerolinecolor='black')
)
fig.show()
Participation Instructions:
- Create - use the weekly data set to build your own Plotly visualization or Dash app. Or, enhance the sample figure provided in this post, using Plotly or Dash.
- Submit - post your creation to LinkedIn or Twitter with the hashtags
#FigureFridayand#plotlyby midnight Thursday, your time zone. Please also submit your visualization as a new post in this thread. - Celebrate - join the Figure Friday sessions to showcase your creation and receive feedback from the community.
![]() If you prefer to collaborate with others on Discord, join the Plotly Discord channel.
If you prefer to collaborate with others on Discord, join the Plotly Discord channel.
Data Source:
Thank you to the World Bank Group for the data (the Monthly Prices link).