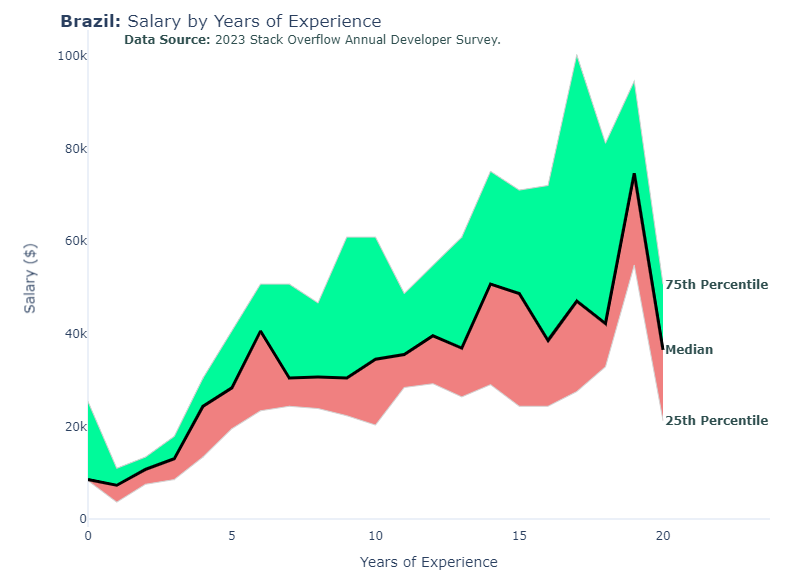
Aug 8: Updated ‘Salary by Years of Experience’ plots. This code still generates the plot with all countries combined, and also makes separate plots by country for countries with more than 1000 survey responses
The graphs show years of experience up to 20 years, and salary statistics (median, 25th percentile and 75th percentile). The code makes 2 plots that were posted earlier this week, and added plots of salary by years of experience. I used go.scatter with mode = ‘lines’ , and color fill between traces. Not clear to me if this could be done using px.line or px.scatter (probably doable, didn’t spend enough time to find out)
import polars as pl
import plotly.express as px
import plotly.graph_objects as go
import pycountry
# Functions
def add_annotation(fig, annotation, x, y, align, xanchor, yanchor, xref='paper', yref='paper', ):
fig.add_annotation(
text=annotation,
xref = xref, x=x, yref = yref, y=y,
align= align, xanchor=xanchor, yanchor=yanchor,
font = {'size': 12, 'color': 'darkslategray'},
showarrow=False
)
return fig
# load dataset to dataframe df_csv
df_csv = pl.read_csv(
f'Dataset/survey_results_public.csv',
ignore_errors=True
)
# create dictionary with countrys as keys, abbreviations as values
dict_countries = {}
for item in pycountry.countries:
dict_countries[item.name] = item.alpha_3
#------------------------------------------------------------------------------#
# AI bias by age group #
#------------------------------------------------------------------------------#
df_ai_age_pct = ( # create and process dataframe
df_csv.lazy() # polars lazy frames
.select('Age', 'AISent')
.filter(~pl.col('Age').is_in(['Prefer not to say','NA']))
.with_columns(
Age = pl.col('Age')
.str.replace('Under 18 years old', '-17')
.str.replace(' years old', '')
.str.replace('65 years or older', '65-'),
)
.with_columns(pl.col('AISent').str.replace('Very favorable','Favorable'))
.with_columns(pl.col('AISent').str.replace('favorable','Favorable'))
.with_columns(pl.col('AISent').str.replace('favorable','Favorable'))
.with_row_index()
.group_by(
pl.col('Age', 'AISent'))
.agg(pl.col("index").count())
.rename({'index': 'Count'})
.with_columns(
PCT = (100 * (pl.col('Count')/pl.col('Count').sum().cast(pl.Float64())).over('Age')),
TOTAL = (pl.col('Count').sum().cast(pl.Float64())).over('Age')
)
.collect() # collect optimizes creation of datframe from lazyframe
)
# Make vertical bar chart
fig = px.bar(
df_ai_age_pct.sort('Age').filter(pl.col('AISent') == 'Favorable'),
x='Age',
y="PCT",
color="Age",
barmode = 'stack',
custom_data = ['Age', 'PCT', 'Count', 'TOTAL']
)
# Setup hover elements
fig.update_traces(
hovertemplate = '<br>'.join([
'Ages %{customdata[0]}',
'%{customdata[1]:.1f}% Favorable',
'%{customdata[2]:,d} of %{customdata[3]:,d}',
'<extra></extra>'
])
)
# Clean up the plot, and display it
fig.update_layout(
title = 'AI Favorabilty, Age Bias',
height=400, width=800,
xaxis_title='Age Group',
yaxis_title='Favorable type response rate (%)',
yaxis_title_font=dict(size=14),
xaxis_title_font=dict(size=14),
margin={"r":50, "t":50, "l":50, "b":50},
autosize=False,
showlegend=False,
template='plotly_white',
)
fig.update_xaxes(showgrid=False)
fig.update_yaxes(showgrid=False, range=[25, 60])
fig.update(layout=dict(barcornerradius=10))
# Add annotations
annotation = "<b>Data Source:</b> 2023 Stack Overflow Annual Developer<br>"
annotation += 'Survey. Favorable type means "Very favorable" or<br>'
annotation += '"Favorable". Age excludes "Prefer not to say" & "NA"<br>'
fig = add_annotation(fig, annotation, 0.5, 1.0, 'left', 'left', 'top')
fig.show()
print('\n\n\n')
#------------------------------------------------------------------------------#
# Average years of professional coding experience by country
#------------------------------------------------------------------------------#
df_coding_years = ( # prepare dataframe
df_csv
.select('Country', 'YearsCodePro')
.filter(~pl.col('YearsCodePro').is_in(['NA']))
# Change country names for USA and UK to match values used by pycountry
.with_columns(pl.col('Country').str.replace('United States of America', 'United States'))
.with_columns(pl.col('Country').str.replace('United Kingdom of Great Britain', 'United Kingdom'))
.with_columns(pl.col('Country').str.replace('United Kingdom and Northern Ireland', 'United Kingdom'))
.with_columns(pl.col('YearsCodePro').str.replace('Less than 1 year', '0'))
.with_columns(pl.col('YearsCodePro').str.replace('More than 50 years', '50'))
.with_columns(pl.col('YearsCodePro').cast(pl.UInt16))
)
# list countries with 1000 or more survey participants
countries_1k = (
df_coding_years
.with_columns(
Country_Count = pl.col('Country').count().over('Country'),
)
.filter(pl.col('Country_Count') > 999)
.filter(pl.col('Country') != 'Other')
.unique('Country')
.sort('Country_Count', descending=True)
['Country'].to_list()
)
# include countries with 1000 or more participants, data between 25th and 75th percentile
df_coding_years = (
df_coding_years
.filter(pl.col('Country').is_in(countries_1k))
.with_columns(
median_years = pl.col('YearsCodePro').median().over('Country'),
Q75 = pl.col('YearsCodePro').quantile(0.75).over('Country'),
Q25 = pl.col('YearsCodePro').quantile(0.25).over('Country')
)
.with_columns(country_abbr = (pl.col('Country')).replace(dict_countries))
.filter(pl.col('YearsCodePro').is_between(pl.col('Q25'),pl.col('Q75')))
.with_columns(average = (pl.col('YearsCodePro').mean().over('Country')))
.with_columns(my_text = (pl.col('Country') + pl.lit(': ') + pl.col('average').round(1).cast(pl.String)))
.sort('median_years')
)
# Create line plot that shows all companies listed in countries_1k
fig = px.line(
df_coding_years.sort('average'),
x='country_abbr',
y='average',
custom_data = ['Country', 'average']
)
fig.update_layout(
title = '<br>Years Professional Coding Experience<br><sup>Countries with at least 1000 survey responses</sup>',
height=400, width=800,
xaxis_title='Country',
yaxis_title='Years (Average)',
yaxis_title_font=dict(size=14),
xaxis_title_font=dict(size=14),
margin={"r":50, "t":50, "l":50, "b":50},
autosize=False,
showlegend=False,
template='plotly_white',
)
# Setup hover elements
fig.update_traces(
mode='markers+lines',
hovertemplate = '<br>'.join([
'%{customdata[0]}',
'%{customdata[1]:.2f} Years',
'<extra></extra>'
])
)
# add scatter plot to emphasize specific countries.
df_focus = df_coding_years.filter(pl.col('country_abbr').is_in(['IND','CAN','USA','AUS']))
fig = fig.add_traces(
px.scatter(
df_focus,
x='country_abbr',
y='average',
text=df_focus['my_text']
).data
)
fig.update_traces(textposition='bottom right')
fig.update_traces(line_color='lightgray', line_width=2, marker_size=10)
# extend x-axis to include all points and annotations
fig.update_xaxes(range=[-1, len(countries_1k)+2.5])
fig.update_xaxes(showgrid=True)
fig.update_yaxes(showgrid=False)
#------------------------------------------------------------------------------#
# Annotate #
#------------------------------------------------------------------------------#
annotation = "<b>Data Source:</b> 2023 Stack Overflow Annual Developer<br>"
annotation += 'Survey. Average includes values between<br>'
annotation += 'quantiles 25 & 75. Arbitrary emphasis on<br>'
annotation += 'min & max averages, and North American countries. '
fig = add_annotation(fig, annotation, 0.05, 0.95, 'left', 'left', 'top')
fig.show()
#------------------------------------------------------------------------------#
# Scatter plot, x is years experience, y is salary
#------------------------------------------------------------------------------#
df_salary = (
df_csv
.select(pl.col('ConvertedCompYearly','WorkExp' ))
.filter(pl.col('ConvertedCompYearly') != 'NA')
.filter(pl.col('WorkExp') != 'NA')
.with_columns(pl.col('WorkExp').cast(pl.Int32))
.with_columns(pl.col('ConvertedCompYearly').cast(pl.Float32))
.filter(
pl.col('ConvertedCompYearly') < 200000,
pl.col('WorkExp') < 21
)
.select(pl.col('ConvertedCompYearly','WorkExp' ))
.with_columns(MEDIAN = pl.col('ConvertedCompYearly').median().over('WorkExp'))
.with_columns(Q25 = pl.col('ConvertedCompYearly').quantile(0.25).over('WorkExp'))
.with_columns(Q75 = pl.col('ConvertedCompYearly').quantile(0.75).over('WorkExp'))
.unique('WorkExp')
.sort('WorkExp')
)
print('\n\n\n')
fig = go.Figure()
fig.add_trace(
go.Scatter(
x=df_salary['WorkExp'],
y=df_salary['Q25'],
fill='none'
)
)
fig.add_trace(
go.Scatter(
x=df_salary['WorkExp'],
y=df_salary['Q75'],
fill='tonexty',
fillcolor='LightCoral'
)
)
fig.add_trace(
go.Scatter(
x=df_salary['WorkExp'],
y=df_salary['MEDIAN'],
fill='tonexty',
fillcolor='MediumSpringGreen'
)
)
fig.update_layout(
title = '<br><b>All Countries:</b> Salary by Years of Experience',
height=600, width=800,
xaxis_title='Years of Experience',
yaxis_title='Salary ($)',
yaxis_title_font=dict(size=14),
xaxis_title_font=dict(size=14),
margin={"r":50, "t":50, "l":50, "b":50},
autosize=False,
showlegend=False,
template='plotly_white',
)
# make median trace thicker (3) than Q25 and Q75 traces (1)
for i, trace in enumerate(fig.data):
trace.line.width = 3 if i == 2 else 1
trace.line.color = 'black' if i == 2 else 'lightgray'
fig.update_xaxes(showgrid=False)
fig.update_yaxes(showgrid=False)
#------------------------------------------------------------------------------#
# Annotations #
#------------------------------------------------------------------------------#
annotation = "<b>Data Source:</b> 2023 Stack Overflow Annual Developer Survey.<br>"
fig = add_annotation(fig, annotation, 0.05, 1.0, 'left', 'left', 'top')
annotation = "<b>Median<br>"
fig = add_annotation(
fig,
annotation,
df_salary['WorkExp'].max(),
df_salary['MEDIAN'][-1],
'left',
'left',
'middle',
xref = 'x',
yref = 'y',
)
annotation = "<b>75th Percentile<br>"
fig = add_annotation(
fig,
annotation,
df_salary['WorkExp'].max(),
df_salary['Q75'][-1],
'left',
'left',
'middle',
xref = 'x',
yref = 'y',
)
annotation = "<b>25th Percentile<br>"
fig = add_annotation(
fig,
annotation,
df_salary['WorkExp'].max(),
df_salary['Q25'][-1],
'left',
'left',
'middle',
xref = 'x',
yref = 'y',
)
fig.show()
#------------------------------------------------------------------------------#
# Scatter plot, by country with 1000 or more response
#------------------------------------------------------------------------------#
for country in countries_1k:
df_salary = (
df_csv
.with_columns(pl.col('Country').str.replace('United States of America', 'United States'))
.with_columns(pl.col('Country').str.replace('United Kingdom of Great Britain', 'United Kingdom'))
.with_columns(pl.col('Country').str.replace('United Kingdom and Northern Ireland', 'United Kingdom'))
.filter(pl.col('Country') == country)
.select(pl.col('ConvertedCompYearly','WorkExp' ))
.filter(pl.col('ConvertedCompYearly') != 'NA')
.filter(pl.col('WorkExp') != 'NA')
.with_columns(pl.col('WorkExp').cast(pl.Int32))
.with_columns(pl.col('ConvertedCompYearly').cast(pl.Float32))
.filter(
pl.col('ConvertedCompYearly') < 200000,
pl.col('WorkExp') < 21
)
.select(pl.col('ConvertedCompYearly','WorkExp' ))
.with_columns(MEDIAN = pl.col('ConvertedCompYearly').median().over('WorkExp'))
.with_columns(Q25 = pl.col('ConvertedCompYearly').quantile(0.25).over('WorkExp'))
.with_columns(Q75 = pl.col('ConvertedCompYearly').quantile(0.75).over('WorkExp'))
.unique('WorkExp')
.sort('WorkExp')
)
print('\n\n\n')
fig = go.Figure()
fig.add_trace(
go.Scatter(
x=df_salary['WorkExp'],
y=df_salary['Q25'],
fill='none'
)
)
fig.add_trace(
go.Scatter(
x=df_salary['WorkExp'],
y=df_salary['Q75'],
fill='tonexty',
fillcolor='LightCoral'
)
)
fig.add_trace(
go.Scatter(
x=df_salary['WorkExp'],
y=df_salary['MEDIAN'],
fill='tonexty',
fillcolor='MediumSpringGreen'
)
)
fig.update_layout(
title = f'<br><b>{country}:</b> Salary by Years of Experience',
height=600, width=800,
xaxis_title='Years of Experience',
yaxis_title='Salary ($)',
yaxis_title_font=dict(size=14),
xaxis_title_font=dict(size=14),
margin={"r":50, "t":50, "l":50, "b":50},
autosize=False,
showlegend=False,
template='plotly_white',
)
# make median trace thicker (3) than Q25 and Q75 traces (1)
for i, trace in enumerate(fig.data):
trace.line.width = 3 if i == 2 else 1
trace.line.color = 'black' if i == 2 else 'lightgray'
fig.update_xaxes(showgrid=False)
fig.update_yaxes(showgrid=False)
#------------------------------------------------------------------------------#
# Annotations #
#------------------------------------------------------------------------------#
annotation = "<b>Data Source:</b> 2023 Stack Overflow Annual Developer Survey.<br>"
fig = add_annotation(fig, annotation, 0.05, 1.0, 'left', 'left', 'top')
if True:
annotation = "<b>Median<br>"
fig = add_annotation(
fig,
annotation,
df_salary['WorkExp'].max(),
df_salary['MEDIAN'][-1],
'left',
'left',
'middle',
xref = 'x',
yref = 'y',
)
annotation = "<b>75th Percentile<br>"
fig = add_annotation(
fig,
annotation,
df_salary['WorkExp'].max(),
df_salary['Q75'][-1],
'left',
'left',
'middle',
xref = 'x',
yref = 'y',
)
annotation = "<b>25th Percentile<br>"
fig = add_annotation(
fig,
annotation,
df_salary['WorkExp'].max(),
df_salary['Q25'][-1],
'left',
'left',
'middle',
xref = 'x',
yref = 'y',
)
fig.show()