Update Sept 28:
Added visualizations to show H1-b visa approvals in a location-approximate grid, inspired by contributions of @empet. One of these visualizations uses go.Scatter, other one uses go.Bar. This data is normalized to show H1-B visa approvals per 1 million residents of each state, with population data of the 2020 census from Kaggle.
These updates are added to the previous code that produced choropleth maps with hover data of states and years.
Here 2 screenshots with the new visualizations:


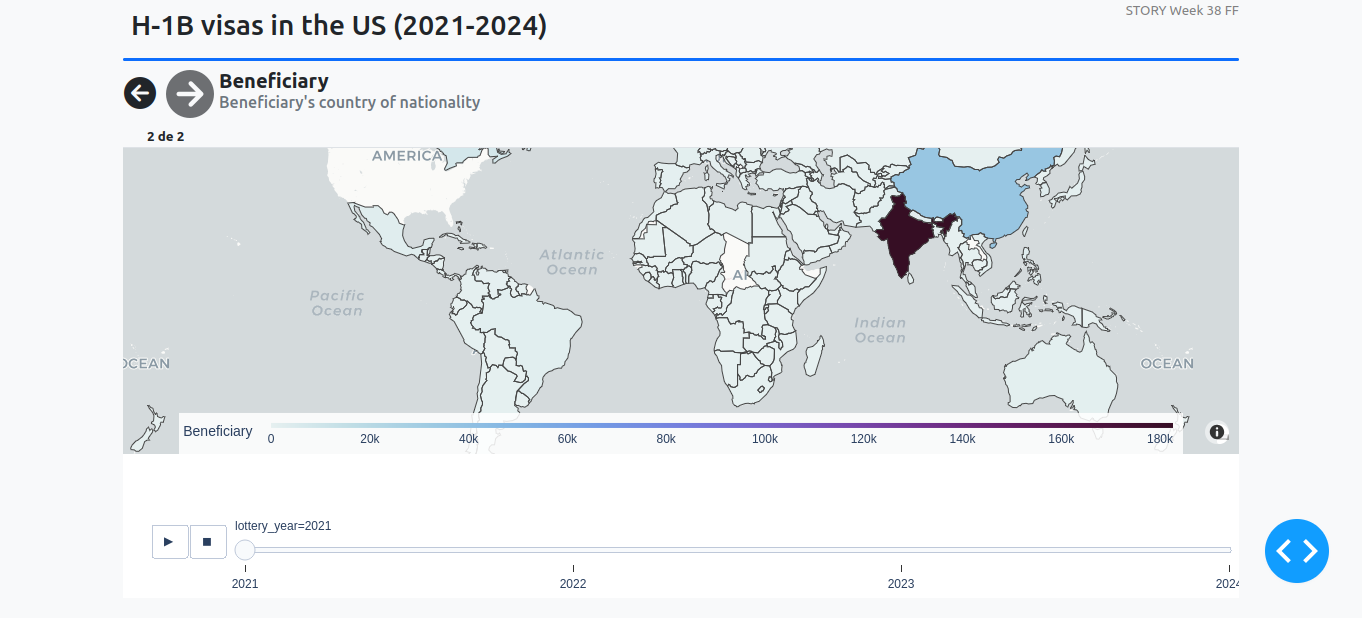
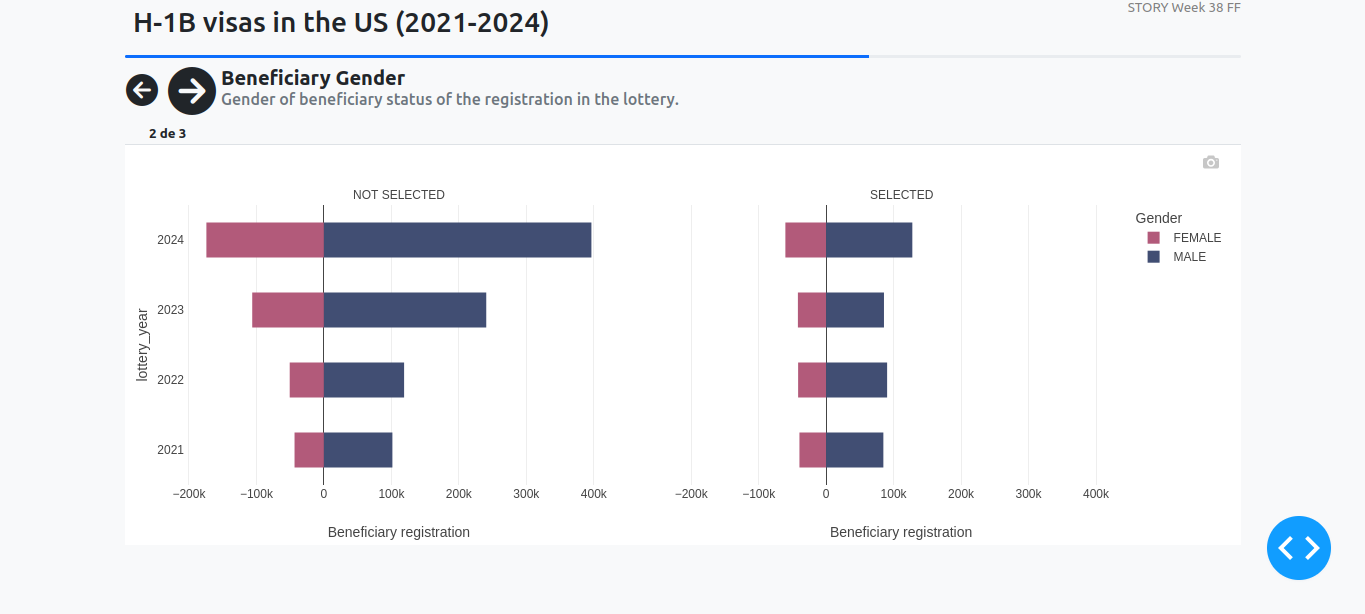
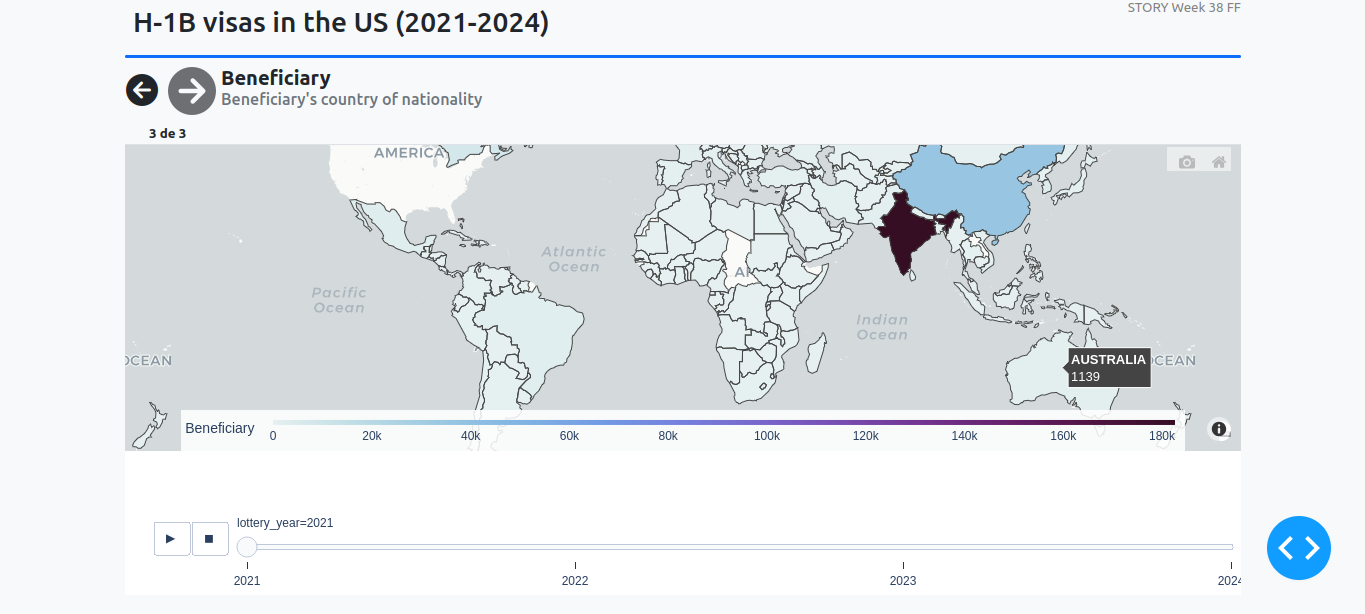
These screenshots were included in my original post for week 38:
Here is the code:
import polars as pl
import polars.selectors as cs
import plotly.express as px
from plotly.subplots import make_subplots
import plotly.graph_objects as go
import numpy as np
import us
#------------------------------------------------------------------------------#
# with us library, make dataframe of state abbreviations and names #
#------------------------------------------------------------------------------#
df_state_names = (
pl.concat( # use concat to add a row for Washington DC
[
pl.DataFrame(us.states.mapping('abbr', 'name'))
.transpose(include_header=True)
.rename({'column': 'STATE_ABBR', 'column_0': 'STATE'})
,
pl.DataFrame(
{
'STATE_ABBR' : 'DC',
'STATE' : 'Washington DC'
}
)
]
)
.sort('STATE_ABBR')
)
#------------------------------------------------------------------------------#
# use kaggle data for state population, join with state names #
#------------------------------------------------------------------------------#
df_state_population = (
pl.read_csv('kaggle_us_pop_by_state.csv')
.rename({'state_code':'STATE_ABBR', '2020_census':'POPULATION'})
.drop_nulls('rank')
.select(pl.col('STATE_ABBR', 'POPULATION'))
.sort('STATE_ABBR')
)
df_state_names = (
df_state_names
.join(
df_state_population,
on='STATE_ABBR',
how='left'
)
)
#------------------------------------------------------------------------------#
# Row and Col #s used with plotly make_subplots. The long rows in #
# # this dataframe definition align with columns in the subplots of states #
#------------------------------------------------------------------------------#
df_state_xy = (
pl.DataFrame(
{
'INFO' : [
['AK', 1, 1], ['WA', 3, 1], ['OR', 4, 1], ['CA', 5, 1], ['HI', 8, 1] ,
['ID', 3, 2], ['NV', 4, 2], ['UT', 5, 2], ['AZ', 6, 2],
['MT', 3, 3], ['WY', 4, 3], ['CO', 5, 3], ['NM', 6, 3],
['ND', 3, 4], ['SD', 4, 4], ['NE', 5, 4], ['KS', 6, 4], ['OK', 7, 4], ['TX', 8, 4],
['MN', 3, 5], ['IA', 4, 5], ['MO', 5, 5], ['AR', 6, 5], ['LA', 7, 5],
['WI', 2, 6], ['IL', 3, 6], ['IN', 4, 6], ['KY', 5, 6], ['TN', 6, 6], ['MS', 7, 6],
['MI', 3, 7], ['OH', 4, 7], ['WV', 5, 7], ['SC', 6, 7], ['AL', 7, 7],
['PA', 4, 8], ['VA', 5, 8], ['NC', 6, 8], ['GA', 7, 8],
['NY', 3, 9], ['NJ', 4, 9], ['MD', 5, 9], ['DC', 6, 9], ['FL', 8, 9],
['VT', 2, 10], ['MA', 3, 10], ['CT', 4, 10], ['DE', 5, 10],
['ME', 1, 11], ['NH', 2, 11], ['RI', 4, 11]
],
},
strict=False
)
# next 3 lines unpack the list column, followed by list column deletion
.with_columns(STATE_ABBR = pl.col('INFO').list.get(0))
.with_columns(ROW = pl.col('INFO').list.get(1).cast(pl.UInt8))
.with_columns(COL = pl.col('INFO').list.get(2).cast(pl.UInt8))
.drop('INFO')
)
#------------------------------------------------------------------------------#
# load data provided for this exercise into polars lazy frames #
#------------------------------------------------------------------------------#
df_2021 = (
pl.scan_csv('./Data_Set/TRK_13139_FY2021.csv',ignore_errors=True)
.filter(pl.col('FIRST_DECISION').str.to_uppercase() == 'APPROVED')
.with_columns(YEAR = pl.lit('2021'))
.with_columns(pl.col('WAGE_AMT').cast(pl.Int64))
.with_columns(pl.col('BEN_COMP_PAID').cast(pl.Int64))
)
df_2022 = (
pl.scan_csv('./Data_Set/TRK_13139_FY2022.csv',ignore_errors=True)
.filter(pl.col('FIRST_DECISION').str.to_uppercase() == 'APPROVED')
.with_columns(YEAR = pl.lit('2022'))
.with_columns(pl.col('WAGE_AMT').cast(pl.Int64))
.with_columns(pl.col('BEN_COMP_PAID').cast(pl.Int64))
)
df_2023 = (
pl.scan_csv('./Data_Set/TRK_13139_FY2023.csv',ignore_errors=True)
.filter(pl.col('FIRST_DECISION').str.to_uppercase() == 'APPROVED')
.with_columns(YEAR = pl.lit('2023'))
.with_columns(pl.col('WAGE_AMT').cast(pl.Int64))
.with_columns(pl.col('BEN_COMP_PAID').cast(pl.Int64))
)
df_2024_multi = (
pl.scan_csv('./Data_Set/TRK_13139_FY2024_multi_reg.csv',ignore_errors=True)
.filter(pl.col('FIRST_DECISION').str.to_uppercase() == 'APPROVED')
.with_columns(YEAR = pl.lit('2024_MULTI'))
.with_columns(pl.col('WAGE_AMT').cast(pl.Int64))
.with_columns(pl.col('BEN_COMP_PAID').cast(pl.Int64))
)
df_2024_single = (
pl.scan_csv('./Data_Set/TRK_13139_FY2024_single_reg.csv',ignore_errors=True)
.filter(pl.col('FIRST_DECISION').str.to_uppercase() == 'APPROVED')
.with_columns(YEAR = pl.lit('2024_SINGLE'))
.with_columns(pl.col('WAGE_AMT').cast(pl.Int64))
.with_columns(pl.col('BEN_COMP_PAID').cast(pl.Int64))
)
#------------------------------------------------------------------------------#
# convert lazy frames to dataframes within the concat block #
#------------------------------------------------------------------------------#
df_all = (
pl.concat(
[
df_2021.collect(),
df_2022.collect(),
df_2023.collect(),
df_2024_multi.collect(),
df_2024_single.collect(),
],
)
)
#------------------------------------------------------------------------------#
# Group by state, calc total of each year, get state name from abbr #
#------------------------------------------------------------------------------#
df_by_state = (
df_all
.rename({'state': 'STATE_ABBR'})
.group_by('STATE_ABBR', 'YEAR')
.agg(pl.len())
.pivot(on='YEAR', index='STATE_ABBR')
.with_columns(TOT_2024 = (pl.col('2024_SINGLE') + pl.col('2024_MULTI')))
.drop('2024_SINGLE', '2024_MULTI')
.rename({'TOT_2024':'2024'})
.with_columns(TOTAL = pl.sum_horizontal(cs.integer()))
.fill_null(strategy="zero")
.join(
df_state_names,
on='STATE_ABBR',
how='left'
)
.select(pl.col('STATE', 'STATE_ABBR', '2021', '2022', '2023', '2024', 'TOTAL' ))
.sort('STATE')
)
#------------------------------------------------------------------------------#
# Assemble hover data #
#------------------------------------------------------------------------------#
customdata=np.stack(
(
df_by_state['STATE'], # customdata[0]
df_by_state['2021'], # customdata[1]
df_by_state['2022'], # customdata[2]
df_by_state['2023'], # customdata[3]
df_by_state['2024'], # customdata[4]
df_by_state['TOTAL'], # customdata[5]
),
axis=-1
)
#------------------------------------------------------------------------------#
# make each state show immigration data. animation frame is commented out #
#------------------------------------------------------------------------------#
fig = px.choropleth(
df_by_state,
geojson="https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json",
locationmode='USA-states',
locations='STATE_ABBR',
color='TOTAL',
scope="usa",
custom_data=['STATE', '2021', '2022', '2023', '2024', 'TOTAL',],
)
#------------------------------------------------------------------------------#
# Update trace with hovertemplate #
#------------------------------------------------------------------------------#
fig.update_traces(
hovertemplate =
'%{customdata[0]}<br>' +
'2021: %{customdata[1]:,}<br>' +
'2022: %{customdata[2]:,}<br>' +
'2023: %{customdata[3]:,}<br>' +
'2024: %{customdata[4]:,}<br>' +
'TOTAL: %{customdata[5]:,}<br>'
'<extra></extra>'
)
fig.update_layout(
margin={"r":1, "t":1, "l":1, "b":1},
showlegend=False
)
fig.write_html(f'Immigration_Map_by_State_Map.html')
fig.show()
#------------------------------------------------------------------------------#
# Prep for subplot display, with px.Scatter of each state #
#------------------------------------------------------------------------------#
df_by_state = (
df_all
.rename({'state': 'STATE_ABBR'})
.group_by('STATE_ABBR', 'YEAR')
.agg(pl.len())
.pivot(on='YEAR', index='STATE_ABBR')
.with_columns(TOT_2024 = (pl.col('2024_SINGLE') + pl.col('2024_MULTI')))
.drop('2024_SINGLE', '2024_MULTI')
.rename({'TOT_2024':'2024'})
.fill_null(strategy="zero")
.join(
df_state_names,
on='STATE_ABBR',
how='left'
)
# calculate totals per 1 Million residents of each state
.with_columns(PER_M_2021 = 1e6* pl.col('2021')/pl.col('POPULATION'))
.with_columns(PER_M_2022 = 1e6 * pl.col('2022')/pl.col('POPULATION'))
.with_columns(PER_M_2023 = 1e6 * pl.col('2023')/pl.col('POPULATION'))
.with_columns(PER_M_2024 = 1e6 * pl.col('2024')/pl.col('POPULATION'))
.select(pl.col('STATE', 'STATE_ABBR', 'PER_M_2021', 'PER_M_2022', 'PER_M_2023', 'PER_M_2024'))
.rename({'PER_M_2021' : '2021', 'PER_M_2022': '2022', 'PER_M_2023': '2023', 'PER_M_2024': '2024' })
.sort('STATE')
.drop('STATE')
.transpose(include_header=True,column_names='STATE_ABBR',header_name='YEAR')
.with_columns(pl.col('YEAR').cast(pl.UInt16))
)
#------------------------------------------------------------------------------#
# Make subplots by state using go.Scatter #
#------------------------------------------------------------------------------#
fig = make_subplots(rows=8, cols=11)
for state in df_state_xy['STATE_ABBR']:
if True: # state not in ['DC']:
my_row = df_state_xy.filter(pl.col('STATE_ABBR') == state)['ROW'][0]
my_col = df_state_xy.filter(pl.col('STATE_ABBR') == state)['COL'][0]
fig.append_trace(go.Scatter(x=df_by_state['YEAR'], y=df_by_state[state]), row=my_row, col=my_col)
fig.update_xaxes(showgrid=False,row=my_row, col=my_col)
fig.update_yaxes(range=[-100,1200],row=my_row, col=my_col)
fig.add_annotation(
xref='x domain',
yref='y domain',
showarrow=False,
x=0.5,
y=1.2,
text='<b>' + state + '</b>',
row=my_row,
col=my_col,
)
if state in ['AK','AZ', 'WI', 'ME', 'VT', 'WA', 'OR', 'CA', 'OK', 'TX', 'HI', 'FL', 'NY']:
fig.update_yaxes(showticklabels=True, row=my_row, col=my_col,)
else:
fig.update_yaxes(showticklabels=False, row=my_row, col=my_col,)
my_title = 'Approved H1-B Visas per Million Residents, 2021 to 2024'
my_title += '<br><sup>USCIS data from Bloomberg, 2020 Census population data from Kaggle</sup>'
fig.update_layout(
title = my_title,
template='plotly_white',
showlegend=False,
height=700,
width=1000
)
fig.update_xaxes(showticklabels=False)
fig.show()
#------------------------------------------------------------------------------#
# Make subplots by state using go.Bar #
#------------------------------------------------------------------------------#
fig = make_subplots(rows=8, cols=11)
for state in df_state_xy['STATE_ABBR']:
if True: # state not in ['DC']:
my_row = df_state_xy.filter(pl.col('STATE_ABBR') == state)['ROW'][0]
my_col = df_state_xy.filter(pl.col('STATE_ABBR') == state)['COL'][0]
fig.append_trace(go.Bar(x=df_by_state['YEAR'], y=df_by_state[state]), row=my_row, col=my_col)
fig.update_xaxes(showgrid=False,row=my_row, col=my_col)
fig.update_yaxes(range=[-100,1200],row=my_row, col=my_col)
fig.add_annotation(
xref='x domain',
yref='y domain',
showarrow=False,
x=0.5,
y=1.2,
text='<b>' + state + '</b>',
row=my_row,
col=my_col,
)
if state in ['AK','AZ', 'WI', 'ME', 'VT', 'WA', 'OR', 'CA', 'OK', 'TX', 'HI', 'FL', 'NY']:
fig.update_yaxes(showticklabels=True, row=my_row, col=my_col,)
else:
fig.update_yaxes(showticklabels=False, row=my_row, col=my_col,)
fig.update_layout(
title = my_title,
template='plotly_white',
showlegend=False,
height=700,
width=1000
)
fig.update_xaxes(showticklabels=False)
fig.show()