Code:
from dash import dcc, html, Input, Output
import dash_bootstrap_components as dbc
import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
# --- Load data ---
df_unemp = pd.read_csv("unemployment.csv")
df_gdp = pd.read_csv("labor-productivity.csv")
df_digital = pd.read_csv("gender-pay-gap.csv") # Actually: female share by income group
df_female = pd.read_csv("gender-parity-in-managerial-positions.csv")
years = sorted(list(set(df_unemp['Year']) & set(df_gdp['Year']) & set(df_digital['Year']) & set(df_female['Year'])))
regions = ['Africa', 'Americas', 'Arab States', 'Asia and the Pacific', 'Europe and Central Asia', 'World']
income_groups = ['Low income', 'Lower-middle income', 'Upper-middle income', 'High income']
color_palette = px.colors.qualitative.Plotly
area_palette = ["#00bcd4", "#ff9800", "#8e24aa", "#43a047"]
bubble_palette = ['#ff9800', '#8e24aa', '#00bcd4']
heatmap_palette = ['#7b1fa2', '#ff7043', '#fff176']
external_stylesheets = [
dbc.themes.BOOTSTRAP,
"https://cdn.jsdelivr.net/npm/bootstrap-icons@1.10.5/font/bootstrap-icons.css"
]
def kpi_card(title, value, icon, color):
"""Return a single KPI card with a white background and colored icon/number."""
return dbc.Card(
dbc.CardBody([
html.Div([
html.I(className=f"bi {icon}", style={"font-size": "2.2rem", "color": color}),
], className="d-flex justify-content-center mb-2"),
html.Div(title, className="mb-2", style={
"fontWeight": "bold",
"fontSize": "1.15rem",
"textAlign": "center"
}),
html.Div(value, style={
"fontWeight": "bold",
"fontSize": "2.3rem",
"color": color,
"textAlign": "center",
"lineHeight": "1.1"
}),
]),
style={
"border": "2px solid #eee",
"borderRadius": "18px",
"background": "#fff",
"color": "#111",
"minWidth": "180px",
"margin": "0 8px",
"padding": "0.5rem",
"boxShadow": "0 2px 8px rgba(0,0,0,0.04)"
},
className="text-center"
)
def chart_card(question, graph_id, height="440px", small_question=False):
"""Return a chart card with a question and a Plotly graph, fixed height."""
return dbc.Card(
dbc.CardBody([
html.H5(question, className="mb-2", style={
"fontWeight": "bold",
"fontSize": "1.05rem" if small_question else "1.25rem",
"whiteSpace": "nowrap" if small_question else "normal",
"overflow": "hidden",
"textOverflow": "ellipsis"
}),
dcc.Graph(id=graph_id, config={"displayModeBar": False}, style={"height": height})
]),
style={
"border": "2px solid #eee",
"borderRadius": "18px",
"background": "#fff",
"margin": "0 8px 24px 8px",
"boxShadow": "0 2px 8px rgba(0,0,0,0.04)",
"height": f"calc({height} + 80px)",
"display": "flex",
"flexDirection": "column",
"justifyContent": "stretch"
}
)
# Custom gradient background CSS and black tab style (active: black, inactive: white)
app = dash.Dash(__name__, external_stylesheets=external_stylesheets)
app.index_string = '''
<!DOCTYPE html>
<html>
<head>
{%metas%}
<title>{%title%}</title>
{%favicon%}
{%css%}
<style>
body {
background: linear-gradient(135deg, #fafdff 0%, #e0f7fa 100%);
}
.custom-tabs .nav-link {
background: #fff !important;
color: #111 !important;
border: 1px solid #111 !important;
border-bottom: none !important;
border-radius: 18px 18px 0 0 !important;
margin-right: 4px;
font-weight: 500;
}
.custom-tabs .nav-link.active {
background: #111 !important;
color: #fff !important;
border: 1px solid #111 !important;
border-bottom: none !important;
}
</style>
</head>
<body>
{%app_entry%}
<footer>
{%config%}
{%scripts%}
{%renderer%}
</footer>
</body>
</html>
'''
app.layout = dbc.Container([
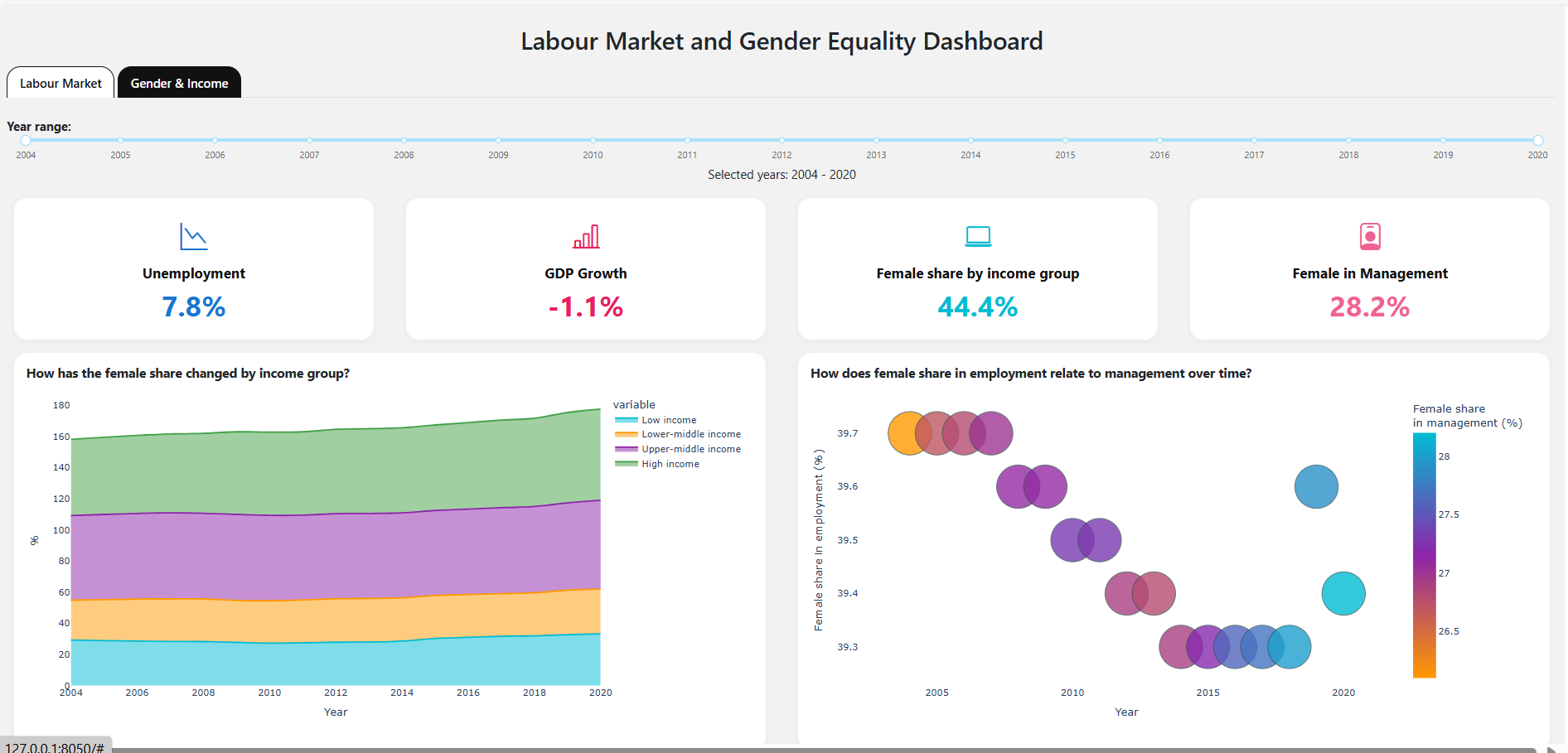
html.H2("Labour Market and Gender Equality Dashboard", className="my-3 text-center"),
dbc.Tabs([
dbc.Tab(
html.Div([
dbc.Row([
dbc.Col(id="kpi-unemp", width=3),
dbc.Col(id="kpi-gdp", width=3),
dbc.Col(id="kpi-digital", width=3),
dbc.Col(id="kpi-mgmt", width=3),
], className="mb-3 justify-content-center"),
dbc.Row([
dbc.Col([
html.Label("Region(s):", style={"fontWeight": "bold"}),
dcc.Dropdown(
id='region-dropdown',
options=[{'label': r, 'value': r} for r in regions],
value=['Africa', 'Americas', 'Europe and Central Asia'],
multi=True,
clearable=False,
style={"fontSize": "0.95rem"}
),
], width=12),
], className="mb-4"),
dbc.Row([
dbc.Col(chart_card(
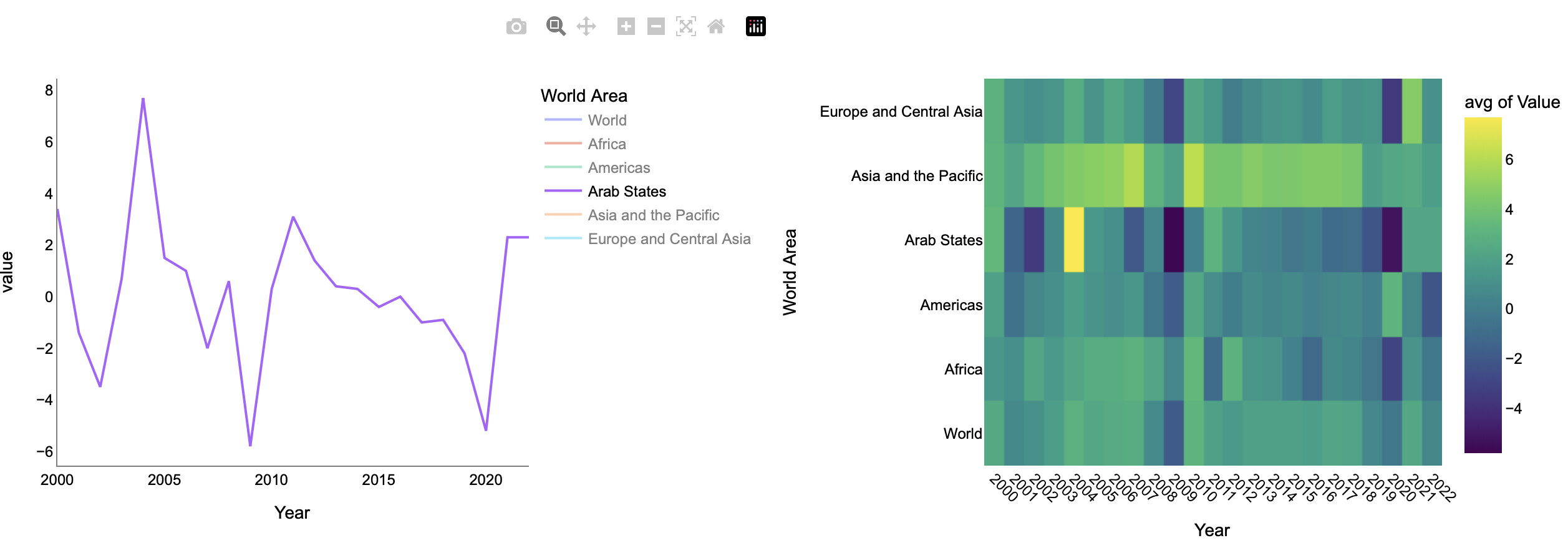
"How has unemployment changed over time in different regions?",
'unemp-line'
), width=6),
dbc.Col(chart_card(
"Which regions and years had the highest or lowest GDP growth?",
'gdp-heatmap'
), width=6),
]),
]),
label="Labour Market",
tab_class_name="custom-tabs"
),
dbc.Tab(
html.Div([
dbc.Row([
dbc.Col(id="kpi-unemp-2", width=3),
dbc.Col(id="kpi-gdp-2", width=3),
dbc.Col(id="kpi-digital-2", width=3),
dbc.Col(id="kpi-mgmt-2", width=3),
], className="mb-3 justify-content-center"),
dbc.Row([
dbc.Col(chart_card(
"How has the female share changed by income group?",
'digital-area',
height="440px",
small_question=True
), width=6),
dbc.Col(chart_card(
"How does female share in employment relate to management over time?",
'female-bubble',
height="440px",
small_question=True
), width=6),
]),
]),
label="Gender & Income",
tab_class_name="custom-tabs"
),
], className="mb-4 custom-tabs"),
], fluid=True, style={"minHeight": "100vh", "padding": "10px 10px"})
@app.callback(
Output('kpi-unemp', 'children'),
Output('kpi-gdp', 'children'),
Output('kpi-digital', 'children'),
Output('kpi-mgmt', 'children'),
Output('kpi-unemp-2', 'children'),
Output('kpi-gdp-2', 'children'),
Output('kpi-digital-2', 'children'),
Output('kpi-mgmt-2', 'children'),
Output('unemp-line', 'figure'),
Output('gdp-heatmap', 'figure'),
Output('digital-area', 'figure'),
Output('female-bubble', 'figure'),
Input('region-dropdown', 'value'),
)
def update_dashboard(regions_selected):
if not isinstance(regions_selected, list):
regions_selected = [regions_selected]
latest_year = max(years)
# --- KPIs (same for both tabs) ---
unemp_row = df_unemp[df_unemp['Year'] == latest_year]
unemp_vals = [unemp_row[r].values[0] for r in regions_selected if not unemp_row.empty and r in unemp_row.columns]
unemp_val = f"{sum(unemp_vals)/len(unemp_vals):.1f}%" if unemp_vals else "-"
kpi1 = kpi_card("Unemployment", unemp_val, "bi-graph-down", "#1976d2")
gdp_row = df_gdp[df_gdp['Year'] == latest_year]
gdp_vals = [gdp_row[r].values[0] for r in regions_selected if not gdp_row.empty and r in gdp_row.columns]
kpi2 = kpi_card("GDP Growth", f"{sum(gdp_vals)/len(gdp_vals):.1f}%" if gdp_vals else "-", "bi-bar-chart-line", "#e91e63")
digital_row = df_digital[df_digital['Year'] == latest_year]
digital_vals = [digital_row[g].values[0] for g in income_groups if not digital_row.empty and g in digital_row.columns]
kpi3 = kpi_card("Female share by income group", f"{sum(digital_vals)/len(digital_vals):.1f}%" if digital_vals else "-", "bi-laptop", "#00bcd4")
mgmt_row = df_female[df_female['Year'] == latest_year]
mgmt_val = mgmt_row['Female share in management'].values[0] if not mgmt_row.empty else None
kpi4 = kpi_card("Female in Management", f"{mgmt_val:.1f}%" if mgmt_val is not None else "-", "bi-person-badge", "#f06292")
# --- Charts ---
# 1. Unemployment line (spline, colored lines, max red marker only, legend right, only regions in legend)
df1 = df_unemp.copy()
fig1 = go.Figure()
for i, region in enumerate(regions_selected):
y = df1[region]
x = df1['Year']
color = color_palette[i % len(color_palette)]
fig1.add_trace(go.Scatter(
x=x, y=y, mode='lines', name=region, line_shape='spline', line=dict(color=color), showlegend=True
))
# Highlight max
max_idx = y.idxmax()
max_year = df1.loc[max_idx, 'Year']
max_val = y[max_idx]
fig1.add_trace(go.Scatter(
x=[max_year], y=[max_val],
mode='markers',
marker=dict(size=14, color='#e53935', line=dict(width=2, color='white')),
name=None,
showlegend=False
))
fig1.update_layout(
yaxis_title="%",
xaxis_title="Year",
legend=dict(orientation="v", x=1.02, y=1, xanchor="left", yanchor="top", bgcolor="rgba(0,0,0,0)"),
margin=dict(l=30, r=120, t=10, b=30),
paper_bgcolor="#fff",
plot_bgcolor="#fff"
)
# 2. GDP heatmap (white-blue-pink-red, so the highest is vivid red)
df_heat = df_gdp.melt(id_vars='Year', var_name='Region', value_name='GDP growth')
df_heat = df_heat[df_heat['Region'].isin(regions_selected)]
heat_pivot = df_heat.pivot(index='Region', columns='Year', values='GDP growth')
fig2 = px.imshow(
heat_pivot,
color_continuous_scale=heatmap_palette,
aspect='auto',
labels=dict(color="GDP growth (%)"),
title=None
) if not heat_pivot.empty else px.imshow([[None]], title="No data")
fig2.update_layout(margin=dict(l=30, r=10, t=10, b=30), paper_bgcolor="#fff", plot_bgcolor="#fff")
# 3. Female share by income group area (area chart, custom palette, white background)
df3 = df_digital.copy()
if not df3.empty:
fig3 = px.area(
df3,
x='Year',
y=income_groups,
title=None,
line_shape="spline",
color_discrete_sequence=area_palette
)
fig3.update_traces(mode="lines")
else:
fig3 = px.area(title="No data")
fig3.update_layout(
yaxis_title="%",
xaxis_title="Year",
margin=dict(l=30, r=10, t=10, b=30),
paper_bgcolor="#fff",
plot_bgcolor="#fff"
)
# 4. Female share in employment vs. management (bubble chart, orange→purple→turquoise scale)
df4 = df_female.copy()
if not df4.empty:
fig4 = px.scatter(
df4,
x='Year',
y='Female share in employment',
size='Female share in the working-age population',
color='Female share in management',
color_continuous_scale=bubble_palette,
title=None
)
else:
fig4 = px.scatter(title="No data")
fig4.update_layout(
yaxis_title="Female share in employment (%)",
xaxis_title="Year",
margin=dict(l=30, r=10, t=10, b=30),
paper_bgcolor="#fff",
plot_bgcolor="#fff"
)
# Show KPIs on both tabs
return kpi1, kpi2, kpi3, kpi4, kpi1, kpi2, kpi3, kpi4, fig1, fig2, fig3, fig4
if __name__ == '__main__':
app.run(debug=True) ```