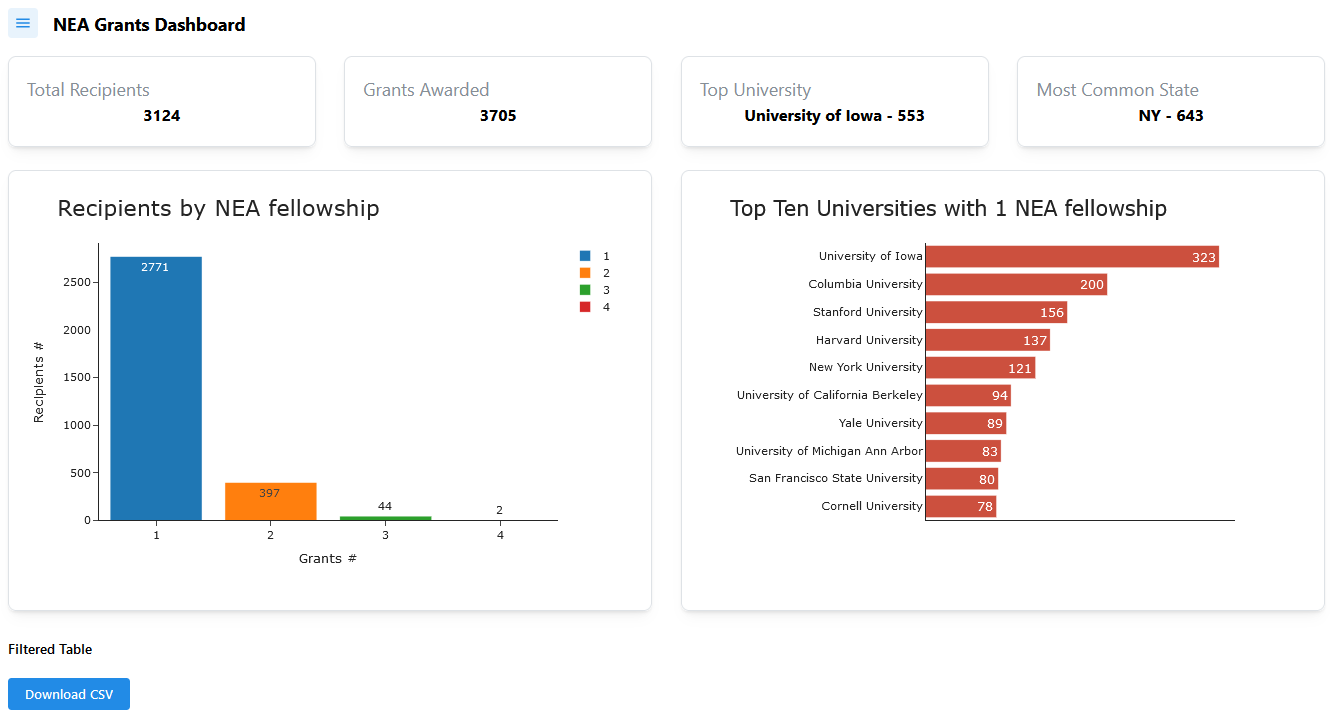
Code
from dash import Dash, dcc, html, Input, Output, State, _dash_renderer, callback, no_update # type: ignore
from dash.exceptions import PreventUpdate # type: ignore
import dash_mantine_components as dmc # type: ignore
import dash_ag_grid as dag # type: ignore
import plotly.express as px # type: ignore
import pandas as pd # type: ignore
from dash_iconify import DashIconify # type: ignore
_dash_renderer._set_react_version("18.2.0")
# df = pd.read_csv("https://raw.githubusercontent.com/plotly/Figure-Friday/refs/heads/main/2025/week-4/Post45_NEAData_Final.csv")
df = pd.read_csv(r'data/Post45_NEAData_Final.csv')
## df1: ids of writters with more than one fellowships, only author's ids with more than one
## df1 ids lookup DataFrame -- 2 cols ['nea_person_id', 'count_grants']
df1 = (df
.loc[df['nea_person_id'].duplicated(keep=False)]
.sort_values(by='nea_person_id') # type: ignore
.groupby(by='nea_person_id', as_index=False)
.agg(count_grants=('nea_person_id','count'))
)
# df writters with more than one NEA fellowship
# df duplicated only with full columns
df_author_more_than_one = (df
.loc[df['nea_person_id'].duplicated(keep=False)]
)
## df with authors with only one fellowship
df_author_one = (df
.loc[~df['nea_person_id'].duplicated(keep=False)]
)
df2 = (df
.groupby(by='nea_person_id', as_index=False) # not grouped as df1
.agg(count_grants=('nea_person_id','count'))
)
## grouped by number of grants
df3 = (df2
.groupby(by='count_grants', as_index=False)
.agg(count_grants_by_autohr=('count_grants','count'))
.astype({'count_grants':'category'})
)
## Top University >>
## University of Iowa with 553 fellowships
# (pd.DataFrame(df
# .loc[:,['ba','ba2','ma','ma2','phd','mfa','mfa2']]
# .stack()).value_counts().reset_index().rename(columns={0:'University'})).loc[0]#,'University']
## Top State >>
## NY with 643 fellowships
# (pd.DataFrame(df
# .loc[:,['us_state']]
# .stack()).value_counts().reset_index().rename(columns={0:'US_State'})).loc[0]#,'University']
## df all Authors with no duplicated 'nea_person_id'
df_all_authors = (df
.loc[~df['nea_person_id'].duplicated(keep='first')] #.assign(author=lambda df_: df_
)
total_recipients = df_all_authors.shape[0] # >> 3214
total_fellowships = df.shape[0] # >> 3705
# df[df['nea_person_id'] == 1953] # https://english.cornell.edu/robert-morgan
# df[df['nea_person_id'] == 437]
# ---------- APP SETUP ----------
app = Dash(__name__, external_stylesheets=dmc.styles.ALL)
# app.title = "NEA Grants Dashboard"
# ---------- 1. NAVIGATION DRAWER (Collapsible) ----------
# A Drawer that will contain filters or navigation items later
nav_drawer = dmc.Drawer(
id="nav-drawer",
title="Filters & Navigation",
padding="md",
size="25%", # up to 1/4 of the screen width
# hideCloseButton=True, # We'll manually control open/close
children=[
dmc.Text("Placeholder for filters / links"),
dmc.Space(h=20),
dmc.Button("Apply Filters (placeholder)", id="apply-filters-btn", fullWidth=True),
],
)
# Button that toggles the drawer
nav_toggle_btn = dmc.ActionIcon(
DashIconify(icon="ic:baseline-menu", width=20),
id="toggle-drawer-btn",
variant="light",
size="lg",
)
# ---------- 2. TOP TOOLBAR ----------
# Contains the drawer toggle button + the main title
top_bar = dmc.Group(
children=[
nav_toggle_btn,
dmc.Text("NEA Grants Dashboard", fw=700, size="xl"),
],
justify="left", # For older DMC versions, use justify="left"
style={"marginTop": "20px", "marginBottom": "20px"},
)
# ---------- 3. SUMMARY CARDS (4 in a responsive Grid) ----------
# We'll create a small helper function for consistent styling
def make_summary_card(title: str, value: str):
return dmc.Card(
children=[
dmc.Text(title, c="dimmed", size="sm", style={"fontSize": 20},),
dmc.Text(value, fw=700, size="xl", ta="center", style={"fontSize": 18},),
],
shadow="sm",
withBorder=True,
radius="md",
style={"padding": "20px"}
)
card_a = make_summary_card("Total Recipients", "3124")
card_b = make_summary_card("Grants Awarded", "3705")
card_c = make_summary_card("Top University", "University of Iowa - 553")
card_d = make_summary_card("Most Common State", "NY - 643")
summary_cards = dmc.Grid(
children=[
dmc.GridCol(card_a, span=3),
dmc.GridCol(card_b, span=3),
dmc.GridCol(card_c, span=3),
dmc.GridCol(card_d, span=3),
],
gutter="xl",
)
# ---------- 4. CHARTS SECTION ----------
# ++++++++++++++++++++ FIG 1 +++++++++++++++++++++++++++++++++
# hover_data=['lifeExp', 'gdpPercap'] adding fields to hover
# hover_data={'col_name':False}, # remove col_name from hover data
fig1 = px.bar(
df3,
x='count_grants',
y='count_grants_by_autohr',
color='count_grants',
template='simple_white',
text_auto=True,
hover_name="count_grants", # column name!
hover_data={'count_grants':False}, # remove 'count_grants' from hover data
labels={'count_grants_by_autohr':'Recipients #',
'count_grants':'Grants #'},
).update_xaxes(type='category').update_layout(legend_title_text='',
title={'text':'Recipients by NEA fellowship',
'font_size':25,
'font_weight':500})
# ++++++++++++++++++++ FIG 2 +++++++++++++++++++++++++++++++++
df_fig100 = (pd.DataFrame(df_author_one
.loc[:,['ba','ba2','ma','ma2','phd','mfa','mfa2']]
.stack())
.value_counts()
.reset_index()
.rename(columns={0:'University'}))
# df_fig100.nlargest(n=20, columns='count').sort_values(by='count')
fig100 = px.bar(
df_fig100.nlargest(n=10, columns='count').sort_values(by='count'),
y='University',
x='count',
# color='orange',
template='simple_white',
text_auto=True,
# hover_name="count_grants", # column name!
# hover_data={'count_grants':False}, # remove 'count_grants' from hover data
labels={'University':'',
'count':''},
).update_layout(legend_title_text='',
title={'text':'Top Ten Universities with 1 NEA fellowship',
'font_size':23,
'font_weight':550})
fig100.update_yaxes(tickfont_weight=550,
ticks='')
fig100.update_xaxes(showticklabels=False,
ticks='')
fig100.update_traces(marker_color='rgb(204,80,62)',
textfont_size=20) # , textangle=0, textposition="outside"
# ---------- 4. CHARTS SECTION ----------
chart_section = dmc.Grid(
[
dmc.GridCol(
dmc.Card(
# children=[
dcc.Graph(
id={"index": "fig1_id"},# 'fig1_id',#
figure=fig1,
),
# dmc.Text('whatever')],
withBorder=True,
my='xs',
shadow="sm",
style={"marginTop": "20px", "padding": "20px"},
radius="md"
),
span={"base": 12, "md": 6},
),
dmc.GridCol(
dmc.Card(
dcc.Graph(
id={"index": "fig2_id"}, # 'fig2_id',#
figure=fig100,
),
withBorder=True,
my='xs',
shadow="sm",
style={"marginTop": "20px", "padding": "20px"},
radius="md"
),
span={"base": 12, "md": 6},
)
],
gutter="xl"
# style={"height": 800}
)
# ---------- 5. TABLE + DOWNLOAD (Placeholder) ----------
table_section = html.Div(
[
dmc.Text("Filtered Table", fw=600, mb=10),
html.Div(id="filtered-table-area",
children=[]), # Will fill dynamically
dcc.Store(id="filtered-data-store", data=[]),
dmc.Group(
[
dmc.Button("Download CSV", id="download-btn", my='xs'),
dcc.Download(id="download-dataframe-csv"),
],
justify="left"
)
],
style={"marginTop": "20px"}
)
# ---------- MAIN LAYOUT CONTAINER ----------
app.layout = dmc.MantineProvider(
dmc.Container(
children=[
nav_drawer, # The drawer is outside the flow, overlays
top_bar, # Toolbar (toggle button + title)
summary_cards, # 4 summary cards in a grid
chart_section, # Main chart or multiple charts
table_section # Table + download button
],
fluid=True,
style={"padding": "20px"}
)
)
# ---------- CALLBACKS ----------
# +++++++++++++++++++++++++++++++
# (A) Toggle the Drawer open/closed
@callback(
Output("nav-drawer", "opened"),
Input("toggle-drawer-btn", "n_clicks"),
State("nav-drawer", "opened"),
prevent_initial_call=True
)
def toggle_nav_drawer(n_clicks, currently_open):
"""When user clicks the hamburger button, toggle the nav drawer."""
if n_clicks:
return not currently_open
return currently_open
# # (B) Apply Filters (placeholder)
# @app.callback(
# Output("filtered-table-area", "children"),
# Input("apply-filters-btn", "n_clicks"),
# prevent_initial_call=True
# )
# def apply_filters(n):
# # For now, just return a placeholder
# return dmc.Text("Table updated.")
# # (C) Update AG Grid table based on clickData
@callback(
Output("filtered-table-area", "children"), # AG Grid inside children
Output("filtered-data-store", 'data'), # dcc.Store() inside table_section
Output({"index": "fig2_id"}, 'figure'), # 2nd chart - Universities chart
Input({"index": "fig1_id"}, "clickData"), # Pattern-matching ID for the left chart
prevent_initial_call=True
)
def update_table_from_bar(clickData):
if not clickData:
raise PreventUpdate
# print(clickData['points'][0]['x']) # string type
# print(type(clickData['points'][0]['x']))
# Extract the x-value from the bar that was clicked
# clickData['points'][0]['x'] => str type
try:
selected_count = int(clickData['points'][0]['x']) # x-axis is "count_grants"
except (IndexError, KeyError):
raise PreventUpdate
# # Filtering df based on bar_chart
if selected_count != 1:
mask = (df1
.loc[df1['count_grants'] == selected_count]
)['nea_person_id'].to_list()
filtered_df = (df
.loc[df['nea_person_id'].isin(mask)] # mask here
).sort_values(by='nea_person_id') # type: ignore
else: # '1'
filtered_df = (df
.loc[~df['nea_person_id'].duplicated(keep=False)]
)
output_data = filtered_df.to_dict("records") # type: ignore
table = dag.AgGrid(
id="table_1",
rowData=output_data,
columnDefs= [{"field": col} for col in df.columns.to_list()],
columnSize="autoSize",
dashGridOptions={
"pagination": True,
"paginationPageSize": 15,
"animateRows": False
},
className="ag-theme-alpine")
if selected_count == 1:
return table, output_data, fig100
else:
# authors with ids according to selected_count greater than 1.-
ids_selected_count = (df1
.loc[df1['count_grants'] == selected_count]
)['nea_person_id'].to_list()
df_mask_selected_count = (df
.loc[:,'nea_person_id']
.isin(ids_selected_count)
)
# filter data from full df suppressing duplicated to count Universities
df_selected_count = (df
.loc[df_mask_selected_count]
.pipe(lambda df_:df_.loc[~df_.duplicated(subset='nea_person_id', keep='first')]) # type: ignore
)
df_fig20 = (pd.DataFrame(df_selected_count
.loc[:,['ba','ba2','ma','ma2','phd','mfa','mfa2']]
.stack())
.value_counts()
.reset_index()
.rename(columns={0:'University'}))
fig20 = px.bar(
df_fig20.nlargest(n=10, columns='count').sort_values(by='count'),
y='University',
x='count',
template='simple_white',
text_auto=True,
labels={'University':'',
'count':''},
)
fig20.update_layout(legend_title_text='',
title={'text':'Top Universities from which they graduated',
'font_size':23,
'font_weight':550},
uniformtext_minsize=12,
)
fig20.update_yaxes(tickfont_weight=550,
ticks='',
)
fig20.update_xaxes(showticklabels=False,
ticks='',
)
fig20.update_traces(marker_color='rgb(204,80,62)',
textfont_size=20,
textangle=0,
)
return table, output_data, fig20
# # (D) Download CSV (placeholder)
@callback(
Output("download-dataframe-csv", "data"),
Input("download-btn", "n_clicks"),
State("filtered-data-store", "data"), # get the stored data
prevent_initial_call=True
)
def download_csv(n_clicks, store_data):
if not store_data:
raise PreventUpdate
else:
df_download = pd.DataFrame(store_data)
return dcc.send_data_frame(df_download.to_csv, filename="filtered_df.csv")
if __name__ == "__main__":
app.run(debug=True, port=8088, jupyter_mode='external')