join the Figure Friday sessions to showcase your creation and receive feedback from the community.
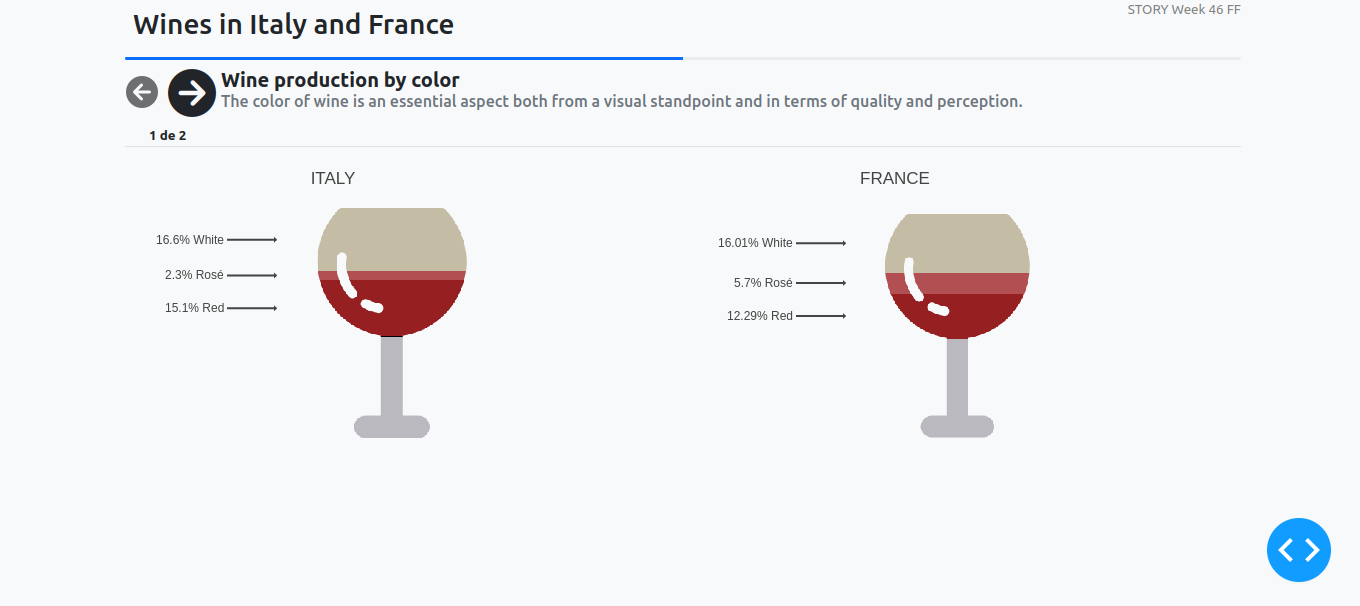
Did you know that Italy and France produce more than half of the wines that fall under the Protected Designation of Origin label within the European Union.
In this week’s data set we’ll explore over 5000 wines from France and Italy together with the wine name, max allowed yields, category, color, registration date and more.
If you’d like to read more about the data, see the respective article in Science Direct.
Things to consider:
- can you improve the sample Violin figure built?
- would a different figure tell the data story better?
- can you create a Dash app instead?
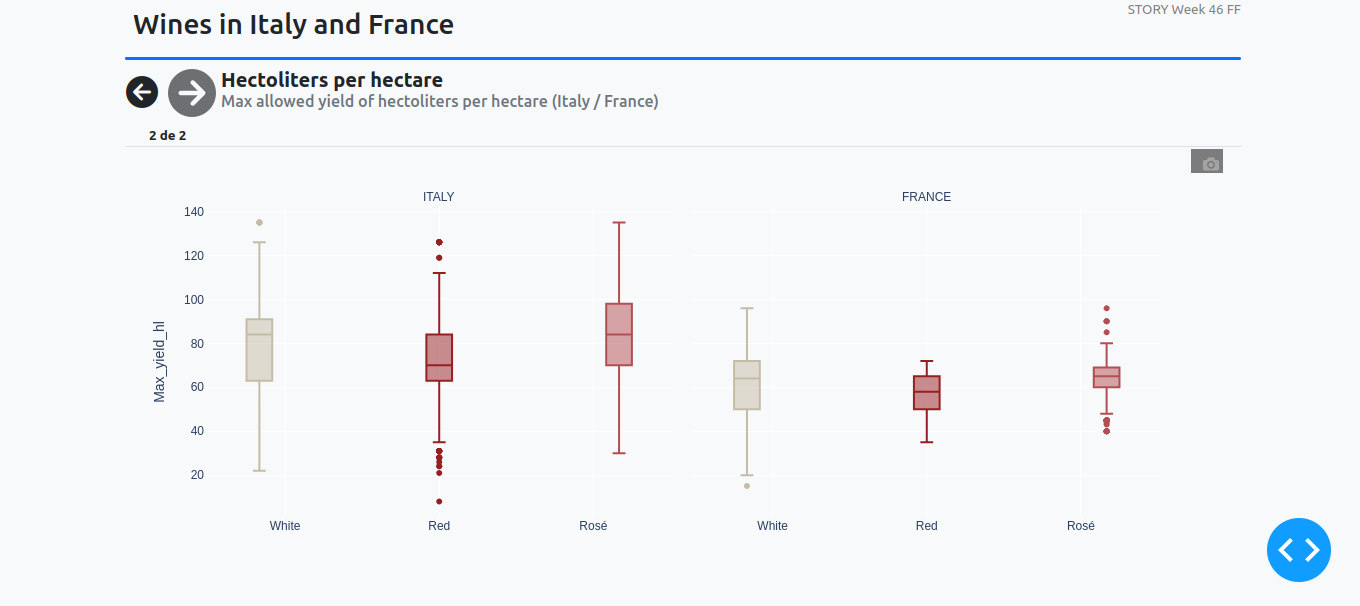
Sample Violin figure:

Code for sample figure:
import plotly.express as px
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/Figure-Friday/refs/heads/main/2024/week-46/PDO_wine_data_IT_FR.csv")
df['Max_yield_hl'] = pd.to_numeric(df['Max_yield_hl'], errors='coerce')
df_cleaned = df.dropna(subset=['Max_yield_hl']) # Remove rows with NaN
fig = px.violin(df_cleaned, x='Color', y='Max_yield_hl',
facet_col='Country',
title="Max allowed yield of hectoliters per hectare (Italy / France)")
fig.show()
Participation Instructions:
- Create - use the weekly data set to build your own Plotly visualization or Dash app. Or, enhance the sample figure provided in this post, using Plotly or Dash.
- Submit - post your creation to LinkedIn or Twitter with the hashtags
#FigureFridayand#plotlyby midnight Thursday, your time zone. Please also submit your visualization as a new post in this thread. - Celebrate - join the Figure Friday sessions to showcase your creation and receive feedback from the community.
![]() If you prefer to collaborate with others on Discord, join the Plotly Discord channel.
If you prefer to collaborate with others on Discord, join the Plotly Discord channel.
Data Source:
Thank you to Sebastian Candiago et al. for the data.