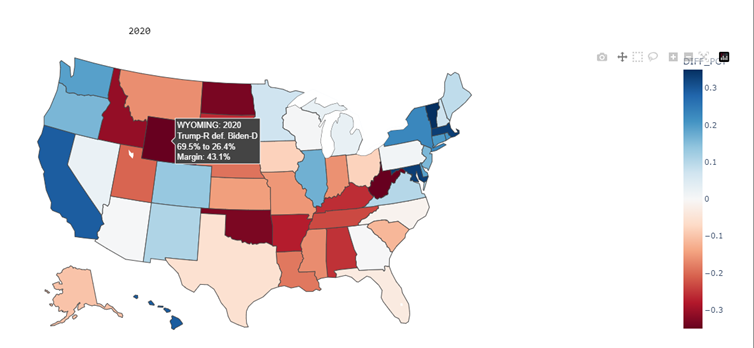
Map can be improved by replacing vote difference with percentage difference as the color value for px.choropleth and updating the color range (I used -35% to +35%). Other improvement is to add more to the hover info
A different story to tell relates to the power of each state’s vote outcome. States with high populations have significantly more electoral votes than states with low populations. All electoral votes of each state are awarded to the winner of that state, with a few minor exceptions where they are split by district (Nebraska & Maine). For example, winner of California will be awared all of its 54 electoral votes, and it doesn’t matter if they win by 1% or win by 90%. This aspect of US presidential elections is very complicated to say the least.
I would say a graph is better than a map for showing how the votes of each state differ over time. I will try this later in the week.
I don’t see any significant advantage of polars or pandas for this exercise. Plotly works seemlessly with either dataframe library. The speed advantage of polars matters for large datasets and computations, I would say not for this one. I use polars to speed up work with very large sets of semiconductor test data. I like the syntax of polars more than pandas, and find it easier to use, so I use if for everything. I used pandas for 5 years though and can’t ignore how much I have grown by using it, and how much it has contributed to my work and my hobbies (including data analysis for a local political party).
One problem I have not solved with this data set is that the hoverinfo would not update correctly when stepping through the animation by year. I will try to fix that. For this first run, the maps are separated by year.
Thank you @adamschroeder for selecting another great dataset for Figure Friday.
In 1976, Georgia was the bluest of the blue states, with election won by native son Jimmy Carter
in 2020, Donald Trump won Wyoming by a margin of 43%, and secured all 3 of its electoral votes out of 538 total for all states and territories.
import plotly.express as px
import plotly.graph_objects as go
import polars as pl
pl.Config().set_tbl_rows(30)
pl.Config().set_tbl_cols(20)
import numpy as np
#------------------------------------------------------------------------------#
# Read dataset from local file, clean up - uses polars LazyFrame #
#------------------------------------------------------------------------------#
keep_columns = [
'candidate', 'year', 'state', 'state_po',
'party_simplified', 'candidatevotes','totalvotes'
]
df = (
pl.scan_csv( # pl.scan_csv creates Lazy Frame for query optimization
'./Dataset/1976-2020-president.csv',
ignore_errors=True
)
.select(
pl.col(keep_columns))
.filter(pl.col('party_simplified').is_in(['DEMOCRAT', 'REPUBLICAN']))
.with_columns(
pl.col('party_simplified')
.str.replace('DEMOCRAT', 'DEM')
.str.replace('REPUBLICAN', 'REP')
)
.filter(pl.col('candidate') != 'OTHER')
.with_columns(
pl.col('candidate')
# for unique candidate family names, fix the Bushes
.str.replace('BUSH, GEORGE H.W.', 'Bush Senior')
.str.replace('BUSH, GEORGE W.', 'Bush Junior')
# for unique candidate family names, fix the Clintons
.str.replace('CLINTON, BILL', 'Clinton B.')
.str.replace('CLINTON, HILLARY', 'Clinton H.')
# ROMNEY, MITT wrongly listed as MITT ROMNEY, Washington 2012
.str.replace('MITT, ROMNEY', 'ROMNEY, MITT'),
pl.col('year').cast(pl.Int16)
)
.with_columns( # get last name of candidate
pl.col('candidate')
.str.split(',')
# .list.slice(0, 1) # gets all text up to first comma
.list.first() # gets all text up to first comma, usually the last name
.str.to_titlecase() # Title case breaks on McCain, next line fixes is
.str.replace('Mccain', 'McCain')
)
# Un-named DEMOCRATIC candidate from ARIZONA in 2016 won 4 votes, drop nulls to remove
.drop_nulls('candidate')
.collect() # collect applies auto-optimization to covert Lazy Frame to usable Data Frame
)
#------------------------------------------------------------------------------#
# Make a list of candidate last names by election year. Special attention #
# for the Bushes (Junior & Senior) & the Clintons (Bill & Hillary) #
#------------------------------------------------------------------------------#
df_candidates = (
df
.select(pl.col('candidate', 'year','party_simplified'))
.unique()
.sort('year')
.pivot(index='year', on='party_simplified', values='candidate')
)
#------------------------------------------------------------------------------#
# Group by year, state, calc difference between DEM_VOTES and REP_VOTES #
#------------------------------------------------------------------------------#
df_votes = (
df
.rename({'totalvotes':'TOT_VOTES'})
.pivot(
index=['year', 'state', 'state_po','TOT_VOTES'], # , 'candidate'],
on ='party_simplified',
values='candidatevotes',
aggregate_function='sum'
)
.with_columns(pl.col('year').cast(pl.Int16))
.rename({'DEM': 'DEM_VOTES', 'REP': 'REP_VOTES'})
)
#------------------------------------------------------------------------------#
# Use a lazy frame to goin df_votes and df_candidates, and finish #
# Remaining calculations #
#------------------------------------------------------------------------------#
final_df = (
pl.LazyFrame(
df_candidates.join(
df_votes,
on='year',
how='left'
)
.with_columns(
DEM_PCT = pl.col('DEM_VOTES') / pl.col('TOT_VOTES'),
REP_PCT = pl.col('REP_VOTES') / pl.col('TOT_VOTES'),
)
.with_columns( # DIFF_PCT is used for coloring each state
DIFF_PCT = pl.col('DEM_PCT') - pl.col('REP_PCT'),
)
.with_columns( # absolute value of vote margin used by hovertemplate
ABS_DIFF_PCT = abs(pl.col('DIFF_PCT'))
)
# make columns with winner's name and party for hovertemplate
.with_columns(
STATE_WINNER =
pl.when(pl.col('DEM_PCT')> pl.col('REP_PCT'))
.then('DEM')
.otherwise('REP'),
WINNING_PARTY =
pl.when(pl.col('DEM_PCT')> pl.col('REP_PCT'))
.then(pl.lit('D'))
.otherwise(pl.lit('R'))
)
# make columns with loser's name and party for hovertemplate
.with_columns(
STATE_LOSER =
pl.when(pl.col('DEM_PCT')> pl.col('REP_PCT'))
.then('REP')
.otherwise('DEM'),
LOSING_PARTY =
pl.when(pl.col('DEM_PCT')> pl.col('REP_PCT'))
.then(pl.lit('R'))
.otherwise(pl.lit('D'))
)
# make column with winers's vote percentage for hovertemplate
.with_columns(
WINNING_PCT =
pl.when(pl.col('DEM_PCT')> pl.col('REP_PCT'))
.then('DEM_PCT')
.otherwise('REP_PCT')
)
# make column with losers's vote percentage for hovertemplate
.with_columns(
LOSING_PCT =
pl.when(pl.col('DEM_PCT')> pl.col('REP_PCT'))
.then('REP_PCT')
.otherwise('DEM_PCT')
)
)
.collect()
)
#------------------------------------------------------------------------------#
# Assemle hover data #
#------------------------------------------------------------------------------#
customdata=np.stack(
(
final_df['state'], # customdata[0]
final_df['year'], # customdata[1]
final_df['STATE_WINNER'], # customdata[2]
final_df['WINNING_PARTY'], # customdata[3]
final_df['STATE_LOSER'], # customdata[4]
final_df['LOSING_PARTY'], # customdata[5]
final_df['WINNING_PCT'], # customdata[6]
final_df['LOSING_PCT'], # customdata[7]
final_df['ABS_DIFF_PCT'] # customdata[8]
),
axis=-1
)
#------------------------------------------------------------------------------#
# make map of each election year #
#------------------------------------------------------------------------------#
for year in sorted(final_df['year'].unique()):
print(year)
year_df = final_df.filter(pl.col('year') == year)
fig = px.choropleth(
year_df,
geojson="https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json",
locationmode='USA-states',
locations='state_po',
color='DIFF_PCT',
scope="usa",
color_continuous_scale=px.colors.diverging.RdBu,
color_continuous_midpoint=0,
range_color=[-0.35,0.35],
animation_frame='year',
custom_data=[
'state', 'year',
'STATE_WINNER', 'WINNING_PARTY',
'STATE_LOSER', 'LOSING_PARTY',
'WINNING_PCT', 'LOSING_PCT',
'ABS_DIFF_PCT'
],
title = str(year)
)
#------------------------------------------------------------------------------#
# Update trace with hovertemplate #
#------------------------------------------------------------------------------#
fig.update_traces(
hovertemplate =
'%{customdata[0]}: %{customdata[1]}<br>' +
'%{customdata[2]}-%{customdata[3]} def. %{customdata[4]}-%{customdata[5]}<br>' +
'%{customdata[6]:.1%} to %{customdata[7]:.1%}<br>' +
'Margin: %{customdata[8]:.1%}<br>' +
'<extra></extra>'
)
fig.update_layout(
margin={"r":0, "t":0, "l":0, "b":0},
)
fig.show()