explainerdashboard
I’d like to share something I’ve been working on lately: a new library to
automatically generate interactive dash apps to explore the inner workings
of machine learning models, called explainerdashboard.
You can build and launch an interactive dashboard to explore the workings
of a fitted machine learning model with a single line of code:
ExplainerDashboard(ClassifierExplainer(RandomForestClassifier().fit(X_train, y_train), X_test, y_test)).run()
Adding a few more lines you can add some functionality and control e.g. over which
tabs are displayed in the dashboard, and on which port it is run:
from sklearn.ensemble import RandomForestClassifier
from explainerdashboard.explainers import *
from explainerdashboard.dashboards import *
from explainerdashboard.datasets import *
X_train, y_train, X_test, y_test = titanic_survive()
train_names, test_names = titanic_names()
model = RandomForestClassifier(n_estimators=50, max_depth=5)
model.fit(X_train, y_train)
explainer = RandomForestClassifierExplainer(model, X_test, y_test,
cats=['Sex', 'Deck', 'Embarked'],
idxs=test_names,
labels=['Not survived', 'Survived'])
db = ExplainerDashboard(explainer, "Titanic Explainer",
model_summary=True,
contributions=True,
shap_dependence=True,
shap_interaction=False, # switch off individual tabs
decision_trees=True)
db.run(port=8051)
The above example is deployed on heroku at titanicexplainer.herokuapp.com.
Installation
The githup repo can be found at https://github.com/oegedijk/explainerdashboard.
You can install the package through pip:
pip install explainerdashboard
Background
The idea behind the package is that with the awesome shap library, it is now
quite straightforward to explain the predictions of so-called “black box” machine
learning models, but it is still quite some interactive manual data science gruntwork
to actually explore the model. The shap library comes with its own plots, but
these are not plotly based so not so easy to build a dashboard out of them.
So I reimplemented all of the shap graphs in plotly, added some additional
functionality (pdp graphs, permutation importances, individual decision tree analysis,
classification and regression plots, etc), and wrapped them all in convenient
classes that handle all of the complexity behind the scenes.
The idea was to make the library as modular as possible so that it would be easy
to build your own dashboards on top of the primitives. But it also comes with
a built-in default dashboard.
So with this library it should be easy to:
- As a data scientist quickly explore your model to understand what it’s doing.
- Allow non-technical stakeholders to explore your model. Either to make sure
there are no problematic features, or in order to understand what the model bases
its decisions on, so they can know for example when to overrule the model. - Explain individual predictions to people affected by your model, and answer
“what if” questions.
Implementation
You first wrap your model in an Explainer object that (lazily) calculates
shap values, permutation importances, partial dependences, shadowtrees, etc.
You can use this Explainer object to interactively query for plots, e.g.:
explainer = ClassifierExplainer(model, X_test, y_test)
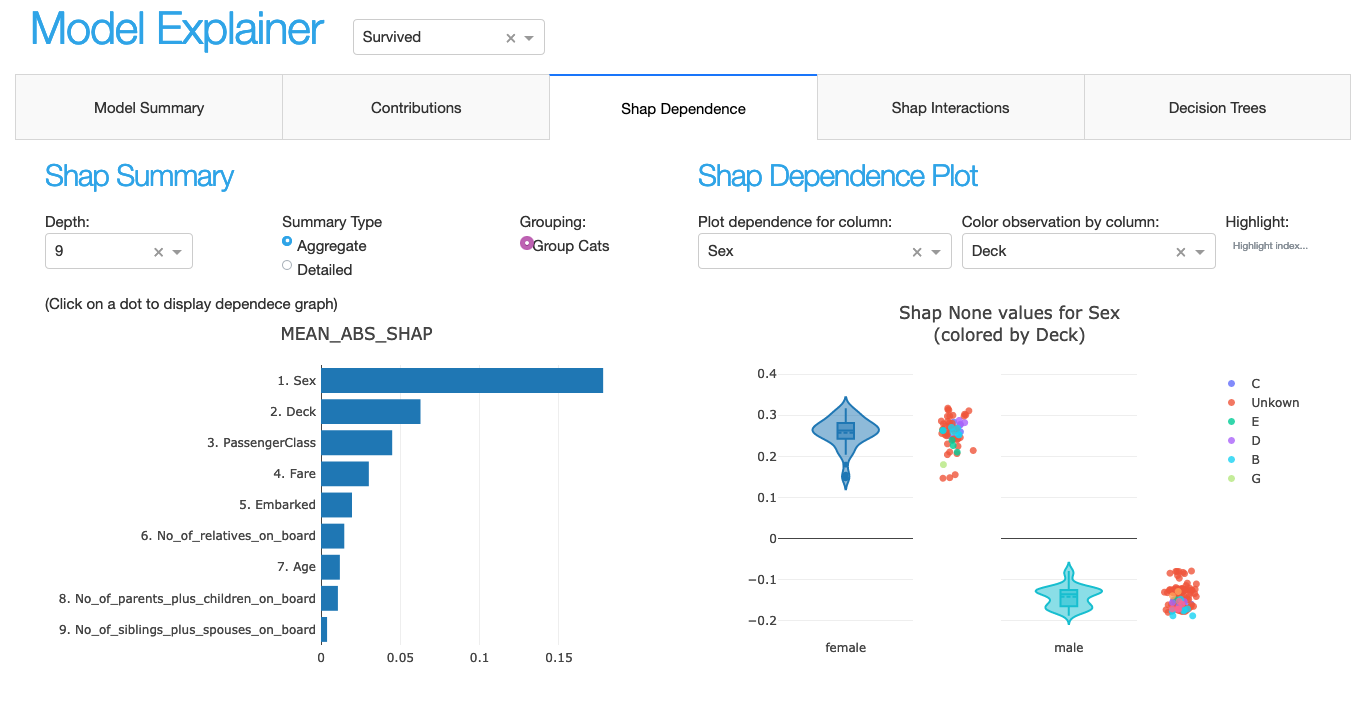
explainer.plot_shap_dependence('Age')
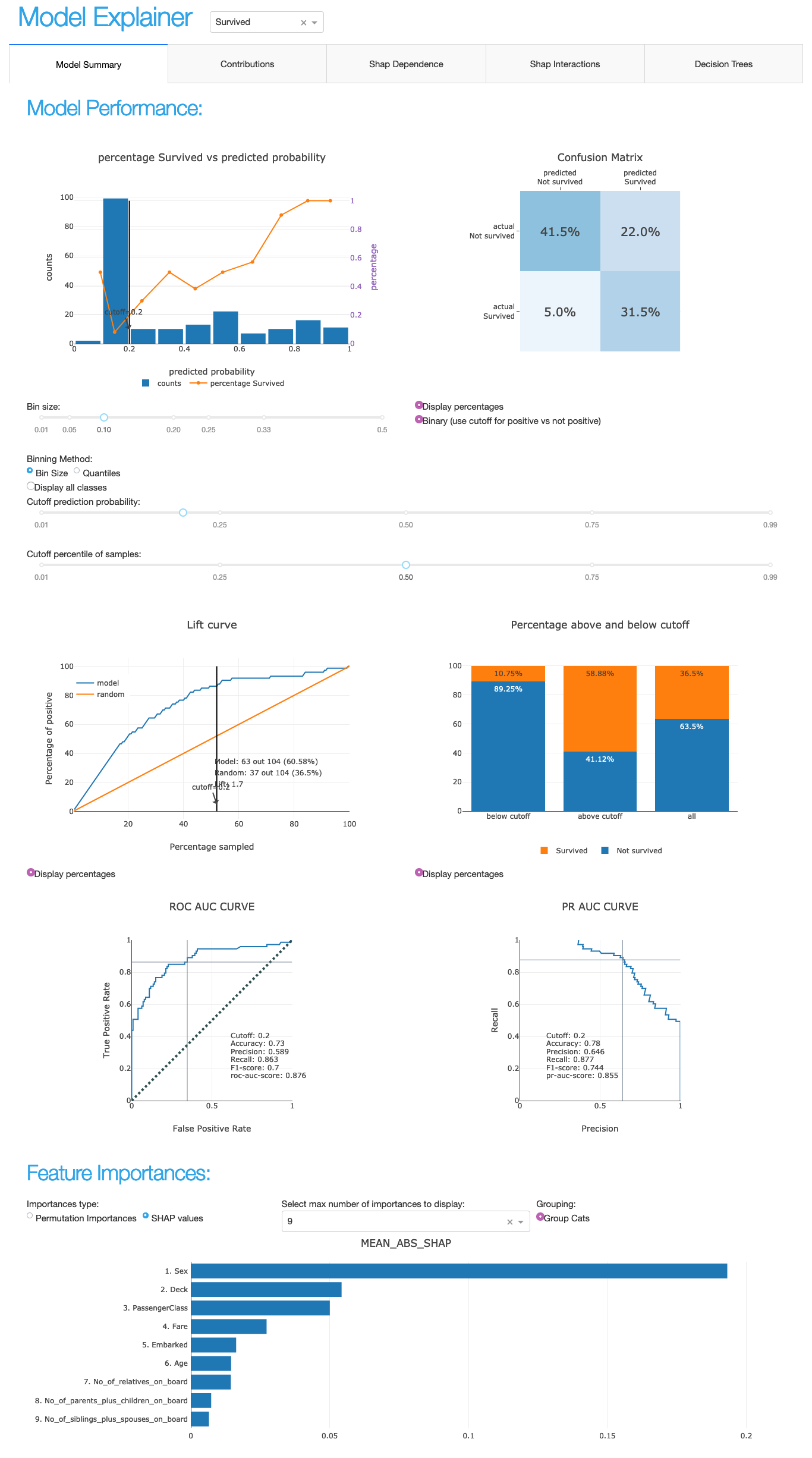
explainer.plot_confusion_matrix(cutoff=0.6, normalized=True)
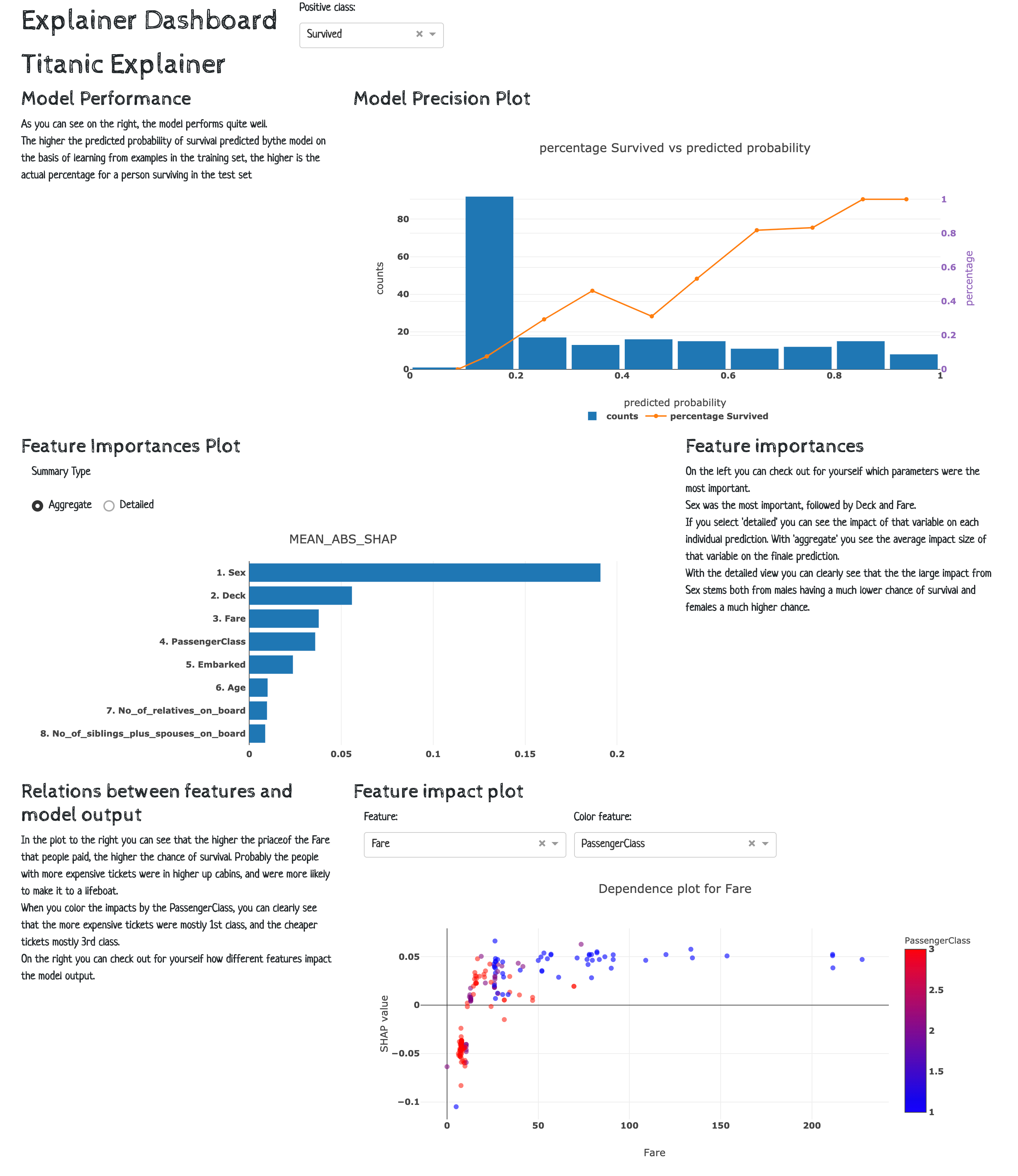
explainer.plot_importances(cats=True)
explainer.plot_pdp('PassengerClass', index=0)
You can then pass this explainer object to an ExplainerDashboard instance
to launch your dashboard. The callbacks in the dash app are quite straightforward
since basically all the logic is already encapsulated by the Explainer object.
db = ExplainerDashboard(explainer, 'Titanic Explainer`,
model_summary=True,
contributions=True,
shap_dependence=True,
shap_interaction=False,
shadow_trees=True)
db.run()
It should be pretty straightforward to build your own dashboard based on the
underlying Explainer object primitives, maybe including more elaboration about
the specific context and interpretation of your particular model.
Supported models
It should work with all models that come in a scikit-learn compatible wrapper
and that are supported by the shap library. I’ve tested it with sklearn models,
XGBoost, LightGBM and CatBoost. However test coverage is not perfect, so let me
know if you run into any problems with any specific model specification.
(e.g.: right now, there are some issues with shap version 0.36 and support for
sklearn RandomForests that stochastically fail on some platforms and XGBoost
version 1.0 and 1.1. Hopefully to be fixed in the next release)
Working within Jupyter
When working inside jupyter you can use JupyterExplainerDashboard() instead
of ExplainerDashboard to use JupyterDash instead of dash.Dash() as a backend
for the app. (this allows you to keep the rest of the notebook interactive while
the app is running, either inline in the cell output or external in a seperate tab)
To simply view a single tab inline in your notebook your can use InlineExplainer:
InlineExplainer(explainer).shap_dependence()
Documentation
An example is deployed at: titanicexplainer.herokuapp.com. (source code on github here)
Documentation can be found at explainerdashboard.readthedocs.io.
Example notebook on how to launch dashboards for different model types here: dashboard_examples.ipynb.
Example notebook on how to interact with the explainer object here: explainer_examples.ipynb.
Ways to contribute
Would love it some of you could try it out and give your feedback. Are there
any issues with particular models/parameterizations that need different default
settings? Weird crashes or failures? Any additional plots or analyses you’d like to see?
Also, I’m not really a trained frontend developer, so if anybody wants to help with
designing a more responsive layout or cooler graphs, let me know!
Also, if anybody is up for building a React.js based decision tree explorer,
that would be really nice to have!