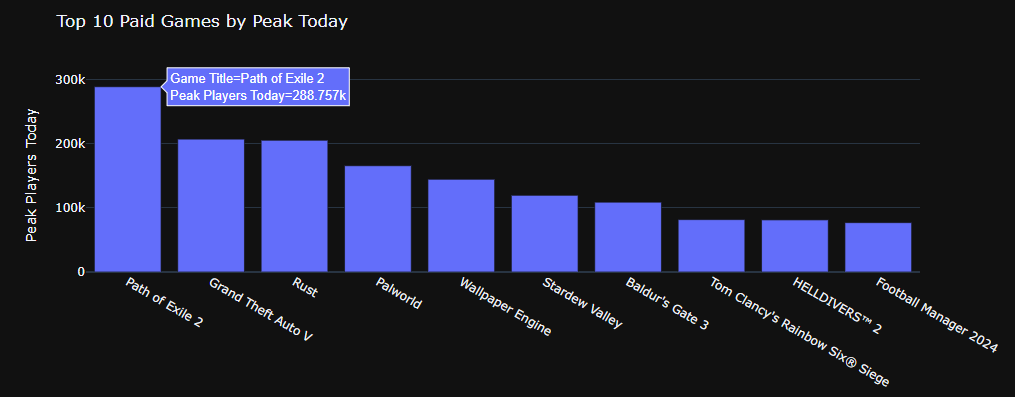
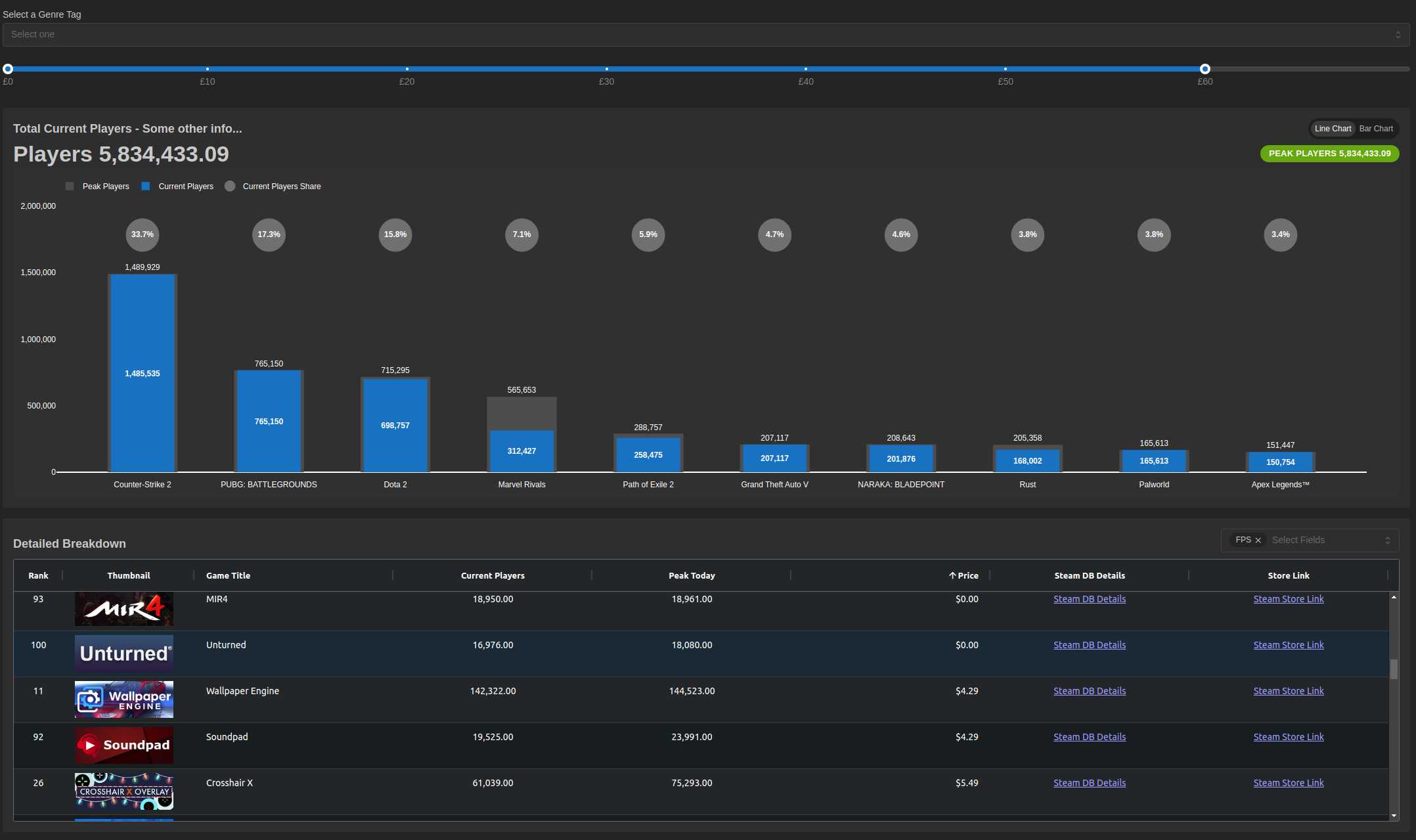
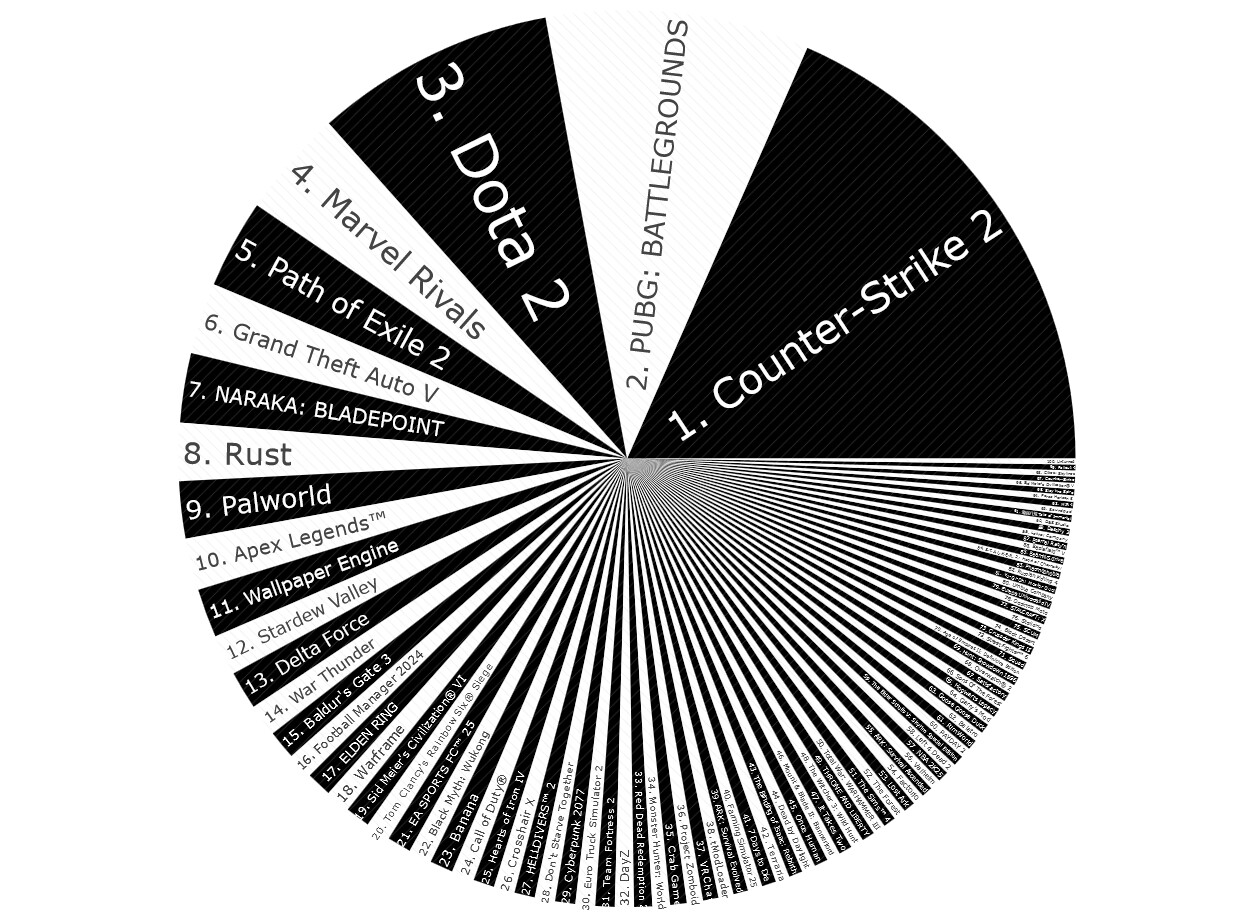
Hello Everyone,
I just follow the same Adams Approach,a just creating a price range to filter the scatter and the bar chart.
The scatter plot is Current Players vs Price but filtering by price range could be interesting, the same filter works for the Bar Chart which is % Difference (Peak vs Current Numbers) by Game
Here attached some images, later on I will upload to py cafe
import dash
from dash import Dash, html, dcc, Output, Input
import plotly.express as px
import numpy as np
import pandas as pd
import dash_bootstrap_components as dbc
df = pd.read_csv("Steam Top 100 Played Games - List.csv")
df["Price"] = df["Price"].replace("Free To Play", 0.0)
df["Price"] = df["Price"].astype(str).str.replace("£", "", regex=False).astype(float)
df["Current Players"] = df["Current Players"].str.replace(",", "").astype(int)
df["Peak Today"] = df["Peak Today"].str.replace(",", "").astype(int)
df['Players diff'] = (((df['Peak Today'] - df['Current Players'])/df['Current Players'])*100).round(2)
external_stylesheets = [dbc.themes.SUPERHERO,'https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.1/css/all.min.css']
price_ranges = {
'Less 12$': (0, 12),
'Between 13-24$': (13, 24),
'Between 25-36$': (25, 36),
'Between 37-48$': (37, 48),
'Between 49-60$': (49, 60)
}
app = dash.Dash(__name__, external_stylesheets=external_stylesheets) # Estilos de Bootstrap
app.title = "Steam Top 100 Games"
# 2. Estructura del layout
app.layout = dbc.Container([
dbc.Row([
html.Hr(className="my-2"),
dbc.Col(html.I(className="fa fa-gamepad", style={"color": "#FD944D", "fontSize": "4rem"}), width=1),
dbc.Col(html.H2("Steam: The Top 100 Most Played Games",className="display-4",
style={'text-align': 'center', 'padding': '10px'}), width=10),
dbc.Col(html.I(className="fa fa-trophy", style={"color": "#FD944D", "fontSize": "4rem"}), width=1)]),
html.Hr(),
html.H4("Price & Popularity: A Steam Game Analysis", style={'text-align': 'center', 'padding': '10px'}),
html.Hr(),
dbc.Row([
dbc.Col(
[
html.H5("Select Price Ranges", style={'text-align': 'left'}),
html.Hr(className="my-2"),
dcc.Checklist(
id='price-checklist',
options=[{'label': label, 'value': label} for label in price_ranges],
value=['Between 25-36$', 'Between 49-60$'],
inline=True,
style={'fontSize': '24px', 'display': 'flex', 'flex-direction': 'row', 'justify-content': 'space-between'},
className="btn btn-secondary"
),
],
width=12
),
],className="navbar navbar-expand-lg bg-primary"),
html.Hr(),
dbc.Tabs(
[
dbc.Tab(label="Impact of Game Prices on Player Numbers", tab_id="tab-1"),
dbc.Tab(label="Player Number Gap (%) by Game (by Price Range)", tab_id="tab-2"),
],
id="tabs",
active_tab="tab-1",
),
html.Div(id="tab-content"),
], fluid=True
)
# 3. Callbacks
@app.callback(
Output("tab-content", "children"),
Input("tabs", "active_tab"),
Input('price-checklist', 'value'),
)
def render_tab_content(active_tab, selected_ranges):
filtered_df = df.copy()
if selected_ranges:
mask = pd.Series(False, index=df.index)
for range_label in selected_ranges:
min_price, max_price = price_ranges[range_label]
mask |= (df['Price'] >= min_price) & (df['Price'] <= max_price)
filtered_df = df[mask]
if active_tab == "tab-1":
# 4. Funciones de gráficos adaptadas
fig = px.scatter(filtered_df, x="Price", y="Current Players", marginal_x="histogram",
template='xgridoff', size='Current Players', size_max=30, hover_name='Name')
fig.update_layout(
xaxis=dict(
title="Price in US$",
titlefont=dict(size=20),
showline=True, showgrid=True, showticklabels=True,
linecolor='rgb(201, 192, 191)', linewidth=3,
ticks='inside', tickfont=dict(family='Arial', size=18, color='rgb(20, 20, 20)')
),
yaxis=dict(
title="Current Players",
titlefont=dict(size=20),
showline=True, showgrid=True, showticklabels=True,
linecolor='rgb(201, 192, 191)', linewidth=3,
ticks='inside', tickfont=dict(family='Arial', size=18, color='rgb(20, 20, 20)')
)
)
fig.update_traces(marker=dict(color='slategray'))
tab_content = dcc.Graph(figure=fig)
elif active_tab == "tab-2":
fig = px.bar(filtered_df.sort_values('Players diff', ascending=False), x='Name', y='Players diff',
template='xgridoff', text_auto=True, labels={'Name':''})
fig.update_layout(
xaxis=dict(
showline=True, showgrid=True, showticklabels=True,
linecolor='rgb(201, 192, 191)', linewidth=3,
ticks='inside', tickfont=dict(family='Arial', size=12, color='rgb(20, 20, 20)')))
fig.update_yaxes(visible=False)
fig.update_traces(marker=dict(color='slategray'))
tab_content = dcc.Graph(figure=fig)
return tab_content
if __name__ == '__main__':
app.run_server(debug=True)type or paste code here`Preformatted text`