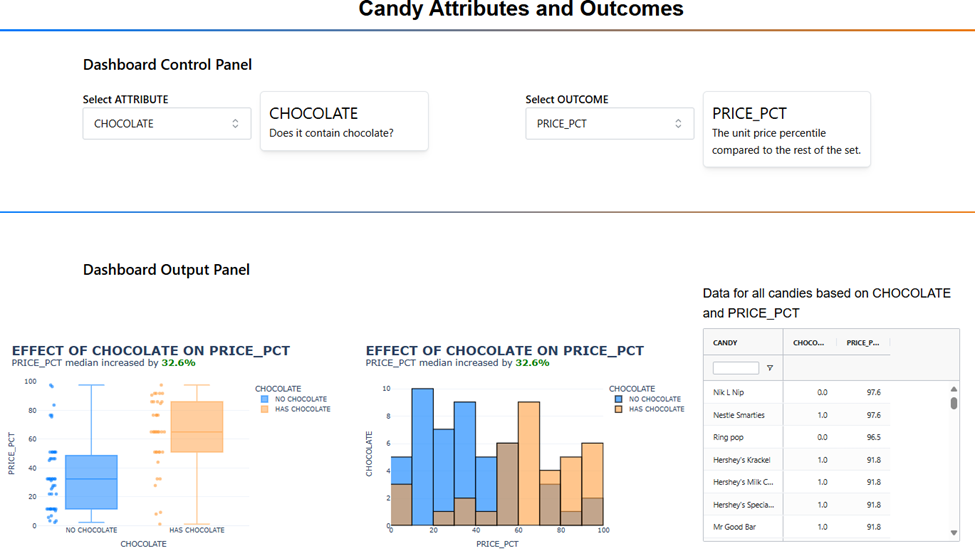
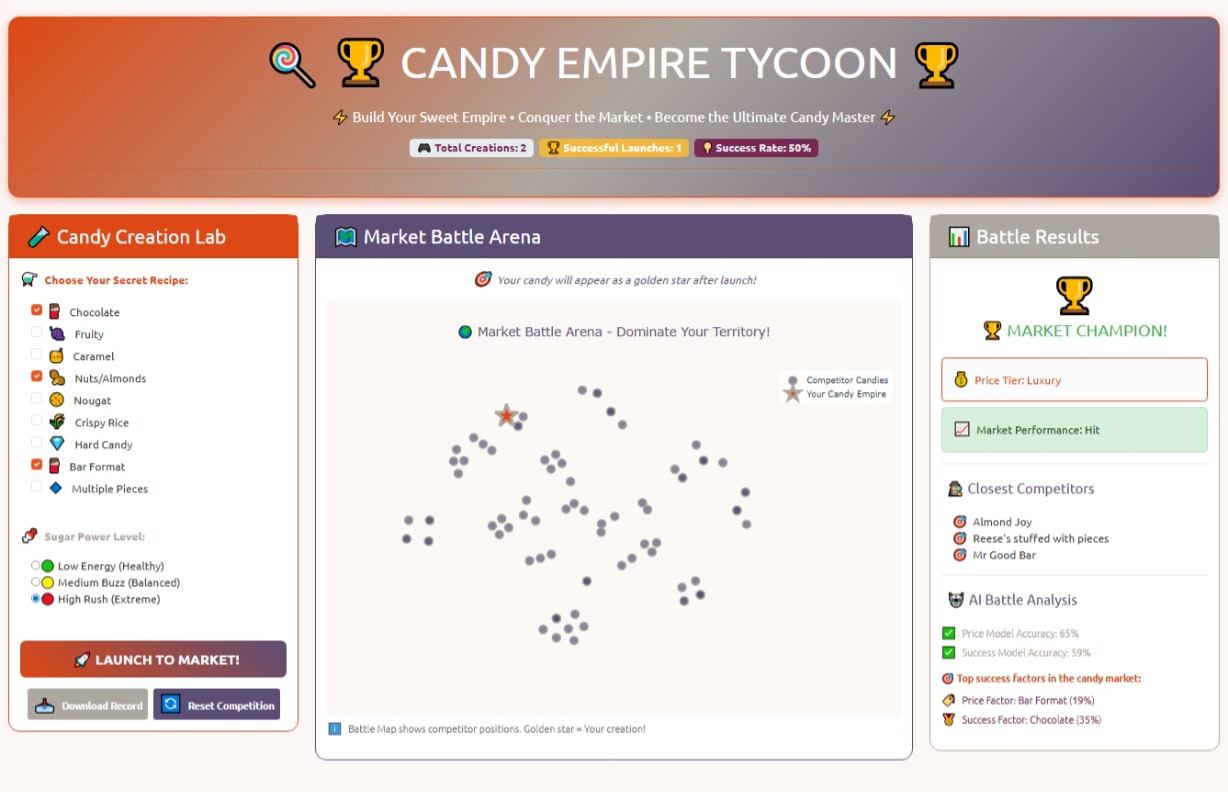
Additionally, it visualizes your creation on a “Market Battle Map” generated with t-SNE, allowing you to see where your new candy stands in relation to the competition.
Feel free to check out the attached code and give it a try. Any comments or suggestions to improve the app or the models are welcome!
The code
import dash
from dash import dcc, html, Input, Output, State
import plotly.graph_objects as go
import pandas as pd
import numpy as np
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.metrics.pairwise import euclidean_distances
Import Dash Bootstrap Components
import dash_bootstrap_components as dbc
================================================================
1. Data Preparation and Machine Learning Models
================================================================
Simulate loading candy-data.csv if it doesn’t exist
To make the code self-contained and executable.
try:
df = pd.read_csv(“candy-data1.csv”)
except FileNotFoundError:
print(“File ‘candy-data.csv’ not found. Creating example DataFrame.”)
data = {
‘competitorname’: [‘100 Grand’, ‘3 Musketeers’, ‘One cup’, ‘Reeses Cup’, ‘Twix’, ‘Snickers’, ‘Kit Kat’, ‘Milky Way’, ‘Baby Ruth’, ‘M&M's’, ‘Sour Patch Kids’, ‘Skittles’],
‘chocolate’: [1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0],
‘fruity’: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1],
‘caramel’: [1, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0],
‘peanutyalmondy’: [0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0],
‘nougat’: [0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0],
‘crispedricewafer’: [1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0],
‘hard’: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
‘bar’: [1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0],
‘pluribus’: [0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1],
‘sugarpercent’: [0.732, 0.604, 0.052, 0.723, 0.546, 0.762, 0.313, 0.604, 0.604, 0.825, 0.069, 0.946],
‘pricepercent’: [0.86, 0.767, 0.116, 0.723, 0.325, 0.651, 0.767, 0.767, 0.767, 0.651, 0.116, 0.325],
‘winpercent’: [66.97, 67.67, 22.84, 82.98, 54.06, 76.67, 72.88, 73.09, 68.53, 66.57, 52.88, 63.08]
}
df = pd.DataFrame(data)
Binarize sugarpercent column into 3 levels (‘low’, ‘medium’, ‘high’)
q1_sugar, q3_sugar = df[‘sugarpercent’].quantile(0.25), df[‘sugarpercent’].quantile(0.75)
def categorize_sugar(x):
if x <= q1_sugar:
return 0
elif x <= q3_sugar:
return 1
else:
return 2
df[‘sugar_level’] = df[‘sugarpercent’].apply(categorize_sugar)
Convert continuous price and popularity variables into categories
df[‘price_level’] = pd.qcut(df[‘pricepercent’], q=3, labels=[‘Budget’, ‘Premium’, ‘Luxury’])
df[‘win_level’] = df[‘winpercent’].apply(lambda x: ‘Hit’ if x > 50 else ‘Flop’)
Use LabelEncoder to convert string labels to numeric
le_price = LabelEncoder()
le_win = LabelEncoder()
df[‘price_level_encoded’] = le_price.fit_transform(df[‘price_level’])
df[‘win_level_encoded’] = le_win.fit_transform(df[‘win_level’])
Define features and labels for the models
feature_columns = [‘chocolate’, ‘fruity’, ‘caramel’, ‘peanutyalmondy’, ‘nougat’,
‘crispedricewafer’, ‘hard’, ‘bar’, ‘pluribus’, ‘sugar_level’]
X = df[feature_columns]
y_price_level_encoded = df[‘price_level_encoded’]
y_win_level_encoded = df[‘win_level_encoded’]
Split data for training and testing (80% training, 20% testing)
X_train_price, X_test_price, y_price_train_encoded, y_price_test_encoded = train_test_split(X, y_price_level_encoded, test_size=0.2, random_state=42)
X_train_win, X_test_win, y_win_train_encoded, y_win_test_encoded = train_test_split(X, y_win_level_encoded, test_size=0.2, random_state=42)
Train ML models on training set
price_model = GradientBoostingClassifier(n_estimators=50, max_depth=2, random_state=42)
price_model.fit(X_train_price, y_price_train_encoded)
X_win_train = pd.concat([X_train_win, pd.Series(y_price_train_encoded, index=X_train_win.index, name=‘price_level_encoded’)], axis=1)
win_model = GradientBoostingClassifier(n_estimators=50, max_depth=2, random_state=42)
win_model.fit(X_win_train, y_win_train_encoded)
Calculate accuracy metrics for both models
y_price_pred_encoded = price_model.predict(X_test_price)
price_accuracy = accuracy_score(y_price_test_encoded, y_price_pred_encoded)
X_win_test_with_price = pd.concat([X_test_win, pd.Series(y_price_pred_encoded, index=X_test_win.index, name=‘price_level_encoded’)], axis=1)
y_win_pred_encoded = win_model.predict(X_win_test_with_price)
win_accuracy = accuracy_score(y_win_test_encoded, y_win_pred_encoded)
Prepare data for t-SNE
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
tsne = TSNE(n_components=2, perplexity=5, random_state=42, init=‘pca’)
X_tsne = tsne.fit_transform(X_scaled)
df[‘TSNE1’] = X_tsne[:, 0]
df[‘TSNE2’] = X_tsne[:, 1]
================================================================
2. Dash Application Setup and Layout (with Dash Bootstrap)
================================================================
Initialize application with United theme
app = dash.Dash(name, external_stylesheets=[dbc.themes.UNITED])
app.title=“Candy Empire Dashboard”
app.layout = dbc.Container([
# Gamified Header
dbc.Row([
dbc.Col(
html.Div(
[
html.Div([
html.Span(“ ”, style={‘font-size’: ‘60px’}, className=“me-3”),
”, style={‘font-size’: ‘60px’}, className=“me-3”),
html.H1(“ CANDY EMPIRE TYCOON”, className=“display-3 d-inline-block”),
CANDY EMPIRE TYCOON”, className=“display-3 d-inline-block”),
html.Span(“”, style={‘font-size’: ‘60px’}, className=“ms-3”),
], className=“d-flex align-items-center justify-content-center mb-3”),
html.P(“ Build Your Sweet Empire • Conquer the Market • Become the Ultimate Candy Master ”, className=“lead”),
Build Your Sweet Empire • Conquer the Market • Become the Ultimate Candy Master ”, className=“lead”),
html.Div(id=“game-stats”, children=[
dbc.Badge(“ Total Creations: 0”, color=“light”, className=“me-2 fs-6 text-dark”),
Total Creations: 0”, color=“light”, className=“me-2 fs-6 text-dark”),
dbc.Badge(“ Successful Launches: 0”, color=“warning”, className=“me-2 fs-6”),
dbc.Badge(“ Success Rate: 0%”, color=“dark”, className=“fs-6 text-light”),
Success Rate: 0%”, color=“dark”, className=“fs-6 text-light”),
], className=“d-flex justify-content-center”),
html.Hr(className=“my-3”, style={‘border-color’: ‘#DD4814’}),
],
className=“p-4 mb-4 rounded-4 text-center text-white”,
style={
‘background’: ‘linear-gradient(135deg, #DD4814 0%, #AEA79F 50%, #5D4E75 100%)’,
‘border’: ‘2px solid #DD4814’,
‘box-shadow’: ‘0 4px 15px rgba(221, 72, 20, 0.4)’
}
),
)
]),
# Main Content with 3-column layout
dbc.Row([
# Column 1: Candy Creation Lab (inside a card)
dbc.Col([
dbc.Card([
dbc.CardHeader([
html.Span(style={'font-size': '30px'}, className="me-2"),
html.H3("🧪 Candy Creation Lab", className="d-inline-block text-center mb-0")
], className="text-white", style={'background-color': '#DD4814'}),
dbc.CardBody([
# Ingredient selection form
html.Div([
dbc.Label([
html.Span("⚗️", style={'font-size': '20px'}, className="me-2"),
"Choose Your Secret Recipe:"
], className="fw-bold mb-3", style={'color': '#DD4814'}),
dbc.Checklist(
id='candy-features-checklist',
options=[
{'label': [html.Span("🍫", style={'font-size': '20px'}, className="me-2"), ' Chocolate'], 'value': 'chocolate'},
{'label': [html.Span("🍇", style={'font-size': '20px'}, className="me-2"), ' Fruity'], 'value': 'fruity'},
{'label': [html.Span("🍯", style={'font-size': '20px'}, className="me-2"), ' Caramel'], 'value': 'caramel'},
{'label': [html.Span("🥜", style={'font-size': '20px'}, className="me-2"), ' Nuts/Almonds'], 'value': 'peanutyalmondy'},
{'label': [html.Span("🍪", style={'font-size': '20px'}, className="me-2"), ' Nougat'], 'value': 'nougat'},
{'label': [html.Span("🌾", style={'font-size': '20px'}, className="me-2"), ' Crispy Rice'], 'value': 'crispedricewafer'},
{'label': [html.Span("💎", style={'font-size': '20px'}, className="me-2"), ' Hard Candy'], 'value': 'hard'},
{'label': [html.Span("🍫", style={'font-size': '20px'}, className="me-2"), ' Bar Format'], 'value': 'bar'},
{'label': [html.Span("🔹", style={'font-size': '20px'}, className="me-2"), ' Multiple Pieces'], 'value': 'pluribus'}
],
value=[],
className="ms-3",
),
], className="mb-4"),
# Sugar level selection
html.Div([
dbc.Label([
html.Span("🍬", style={'font-size': '20px'}, className="me-2"),
"Sugar Power Level:"
], className="fw-bold mt-3 mb-3", style={'color': '#AEA79F'}),
dcc.RadioItems(
id='sugar-level-radio',
options=[
{'label': '🟢 Low Energy (Healthy)', 'value': 0},
{'label': '🟡 Medium Buzz (Balanced)', 'value': 1},
{'label': '🔴 High Rush (Extreme)', 'value': 2}
],
value=1,
className="ms-3"
)
], className="mb-4"),
# Launch button
html.Div(
dbc.Button([
html.Span(style={'font-size': '25px'}, className="me-2"),
"🚀 LAUNCH TO MARKET!"
], id="launch-button", n_clicks=0,
size="lg", className="mt-4 fw-bold text-white",
style={'background': 'linear-gradient(45deg, #DD4814, #5D4E75)', 'border': 'none'}),
className="d-grid gap-2"
),
# New buttons for download and reset
html.Div([
dbc.Button([
html.Span("📥", style={'font-size': '25px'}, className="me-2"),
"Download Record"
], id="download-button", n_clicks=0,
size="sm", className="me-2 mt-3 fw-bold text-white",
style={'background-color': '#AEA79F', 'border': 'none'}),
dcc.Download(id="download-data"),
dbc.Button([
html.Span("🔄", style={'font-size': '25px'}, className="me-2"),
"Reset Competition"
], id="reset-button", n_clicks=0,
size="sm", className="mt-3 fw-bold text-white",
style={'background-color': '#5D4E75', 'border': 'none'})
], className="d-flex justify-content-center"),
])
], className="rounded-4", style={'border': '2px solid #DD4814'}),
], md=3, className="mb-4"),
# Column 2: Market Battle Map (inside a card)
dbc.Col([
dbc.Card([
dbc.CardHeader([
html.Span(style={'font-size': '30px'}, className="me-2"),
html.H3("🗺️ Market Battle Arena", className="d-inline-block text-center mb-0")
], className="text-white", style={'background-color': '#5D4E75'}),
dbc.CardBody([
html.P([
html.Span("🎯", style={'font-size': '20px'}, className="me-2"),
"Your candy will appear as a golden star after launch!"
], className="text-center fst-italic", style={'color': '#5D4E75'}),
dcc.Graph(id="tsne-market-map", style={'height': '600px'}),
html.P([
html.Span("ℹ️", style={'font-size': '16px'}, className="me-2"),
"Battle Map shows competitor positions. Golden star = Your creation!"
], className="text-muted mt-2 small")
])
], className="rounded-4", style={'border': '2px solid #5D4E75'})
], md=6, className="mb-4"),
# Column 3: Battle Results (inside a card)
dbc.Col([
dbc.Card([
dbc.CardHeader([
html.Span(style={'font-size': '30px'}, className="me-2"),
html.H3("📊 Battle Results", className="d-inline-block text-center mb-0")
], className="text-white", style={'background-color': '#AEA79F'}),
dbc.CardBody(id="prediction-results"),
], className="rounded-4", style={'border': '2px solid #AEA79F'})
], md=3, className="mb-4"),
], className="g-4"),
# Stores for game state and history
dcc.Store(id='game-state-store', data={'successful_launches': 0, 'total_launches': 0}),
dcc.Store(id='history-store', data=[]),
], fluid=True, className=“py-4”, style={‘background-color’: ‘#FCF7F5’})
================================================================
3. Callbacks for Application Logic
================================================================
@app.callback(
[Output(“tsne-market-map”, “figure”),
Output(“prediction-results”, “children”),
Output(“game-stats”, “children”),
Output(“game-state-store”, “data”),
Output(“history-store”, “data”)],
[Input(“launch-button”, “n_clicks”)],
[State(“candy-features-checklist”, “value”),
State(“sugar-level-radio”, “value”),
State(“game-state-store”, “data”),
State(“history-store”, “data”)]
)
def launch_candy(n_clicks, selected_features, sugar_level, game_data, history_data):
# Get current stats from stored data
current_total = game_data.get(‘total_launches’, 0)
current_successful = game_data.get(‘successful_launches’, 0)
# Create initial stats badges
stats_badges = [
dbc.Badge(f"🎮 Total Creations: {current_total}", color="light", className="me-2 fs-6 text-dark"),
dbc.Badge(f"🏆 Successful Launches: {current_successful}", color="warning", className="me-2 fs-6"),
dbc.Badge(f"💡 Success Rate: {(current_successful/current_total*100) if current_total > 0 else 0:.0f}%", color="dark", className="fs-6 text-light"),
]
if n_clicks == 0:
# Initial state of the graph
fig = create_market_map(None, df['TSNE1'], df['TSNE2'])
return fig, html.Div([
html.Div([
html.Span("⏰", style={'font-size': '40px'}, className="mb-3"),
html.H5("⏳ Ready for Launch", className="text-center mb-3", style={'color': '#DD4814'}),
html.P("Create your candy recipe and launch it to see how it performs in the market battle!", className="text-secondary")
], className="text-center")
]), stats_badges, game_data, history_data
# Convert user selections into feature vector
user_features = {
'chocolate': 0, 'fruity': 0, 'caramel': 0, 'peanutyalmondy': 0, 'nougat': 0,
'crispedricewafer': 0, 'hard': 0, 'bar': 0, 'pluribus': 0
}
for feature in selected_features:
user_features[feature] = 1
# Add sugar level
user_features['sugar_level'] = sugar_level
# Create DataFrame for prediction
new_candy_df = pd.DataFrame([user_features])
# Predict price category
predicted_price_level_encoded = price_model.predict(new_candy_df[feature_columns])[0]
predicted_price_level = le_price.inverse_transform([predicted_price_level_encoded])[0]
# Predict popularity category using predicted price category
new_candy_for_win_level = new_candy_df.copy()
new_candy_for_win_level['price_level_encoded'] = predicted_price_level_encoded
predicted_win_level_encoded = win_model.predict(new_candy_for_win_level[feature_columns + ['price_level_encoded']])[0]
predicted_win_level = le_win.inverse_transform([predicted_win_level_encoded])[0]
# Recalculate t-SNE with the new candy
combined_df = pd.concat([df[feature_columns], new_candy_df[feature_columns]], ignore_index=True)
combined_scaled = scaler.fit_transform(combined_df)
combined_tsne = tsne.fit_transform(combined_scaled)
new_candy_tsne_coords = combined_tsne[-1]
# --- Find closest competitors using Euclidean Distance ---
existing_candies_features = X.values
new_candy_feature_vector = new_candy_df[feature_columns].values
distances = euclidean_distances(new_candy_feature_vector, existing_candies_features)
closest_indices = np.argsort(distances[0])[:3]
closest_competitors = df.iloc[closest_indices]['competitorname'].tolist()
fig = create_market_map({'TSNE1': new_candy_tsne_coords[0], 'TSNE2': new_candy_tsne_coords[1]}, combined_tsne[:-1, 0], combined_tsne[:-1, 1])
# Get feature importance for models
price_importances = pd.Series(price_model.feature_importances_, index=feature_columns).sort_values(ascending=False)
win_importances = pd.Series(win_model.feature_importances_, index=feature_columns + ['price_level_encoded']).sort_values(ascending=False)
# Convert feature names to readable format
feature_labels = {
'chocolate': 'Chocolate', 'fruity': 'Fruity', 'caramel': 'Caramel', 'peanutyalmondy': 'Nuts/Almonds',
'nougat': 'Nougat', 'crispedricewafer': 'Crispy Rice', 'hard': 'Hard Candy', 'bar': 'Bar Format',
'pluribus': 'Multiple Pieces', 'sugar_level': 'Sugar Level', 'price_level_encoded': 'Price Tier'
}
# Calculate new totals
new_total = current_total + 1
new_successful = current_successful
# Determine battle result and update success counter
if predicted_win_level == 'Hit':
result_icon = "🏆"
result_color = "success"
result_text = "🏆 MARKET CHAMPION!"
new_successful += 1
else:
result_icon = "💔"
result_color = "secondary"
result_text = "💔 Market Flop"
# Update stats badges with corrected counts
updated_stats_badges = [
dbc.Badge(f"🎮 Total Creations: {new_total}", color="light", className="me-2 fs-6 text-dark"),
dbc.Badge(f"🏆 Successful Launches: {new_successful}", color="warning", className="me-2 fs-6"),
dbc.Badge(f"💡 Success Rate: {(new_successful/new_total*100):.0f}%", color="dark", className="fs-6 text-light"),
]
# Update game state
updated_game_data = {
'successful_launches': new_successful,
'total_launches': new_total
}
# --- NEW: Append to history data ---
new_launch_record = {
'launch_id': new_total,
'features': [feature_labels[f] for f in selected_features] + [feature_labels['sugar_level']],
'predicted_price': predicted_price_level,
'predicted_win': predicted_win_level,
'closest_competitors': closest_competitors
}
history_data.append(new_launch_record)
# Prepare results to display
results = [
html.Div([
html.Span(result_icon, style={'font-size': '50px'}, className="mb-2"),
html.H4(result_text, className=f"text-center text-{result_color}")
], className="text-center mb-4"),
dbc.Alert([
html.Span("💰", style={'font-size': '20px'}, className="me-2"),
f"Price Tier: {predicted_price_level}"
], color="light", className="mb-2", style={'border-color': '#DD4814', 'color': '#DD4814'}),
dbc.Alert([
html.Span("📈", style={'font-size': '20px'}, className="me-2"),
f"Market Performance: {predicted_win_level}"
], color=result_color, className="mb-3"),
html.Hr(style={'border-color': '#AEA79F'}),
html.Div([
html.Span(style={'font-size': '25px'}, className="me-2"),
html.H5("🕵️ Closest Competitors", className="d-inline-block", style={'color': '#5D4E75'})
], className="mb-3"),
html.Ul([
html.Li([
html.Span("🎯", style={'font-size': '16px'}, className="me-2"),
competitor
]) for competitor in closest_competitors
], className="list-unstyled", style={'padding-left': '1rem'}),
html.Hr(style={'border-color': '#AEA79F'}),
html.Div([
html.Span(style={'font-size': '25px'}, className="me-2"),
html.H5("🤖 AI Battle Analysis", className="d-inline-block", style={'color': '#5D4E75'})
], className="mb-3"),
html.P([
html.Span("✅", style={'font-size': '16px'}, className="me-2"),
f"Price Model Accuracy: {price_accuracy:.0%}"
], className="mb-1 text-secondary small"),
html.P([
html.Span("✅", style={'font-size': '16px'}, className="me-2"),
f"Success Model Accuracy: {win_accuracy:.0%}"
], className="mb-3 text-secondary small"),
html.P("🎯 Top success factors in the candy market:", className="fw-bold mb-2 small", style={'color': '#DD4814'}),
html.P([
html.Span("🏷️", style={'font-size': '16px'}, className="me-2"),
f"Price Factor: {feature_labels[price_importances.index[0]]} ({price_importances.iloc[0]:.0%})"
], className="text-dark small mb-1"),
html.P([
html.Span("🥇", style={'font-size': '16px'}, className="me-2"),
f"Success Factor: {feature_labels[win_importances.index[0]]} ({win_importances.iloc[0]:.0%})"
], className="text-dark small"),
]
return fig, results, updated_stats_badges, updated_game_data, history_data
— MODIFIED CALLBACK: Download button functionality for .txt —
@app.callback(
Output(“download-data”, “data”),
Input(“download-button”, “n_clicks”),
State(“history-store”, “data”),
prevent_initial_call=True
)
def download_history(n_clicks, history_data):
# Ensure a dictionary is always returned, even if history is empty
records =
for record in history_data:
records.append({
‘Launch_ID’: record[‘launch_id’],
‘Ingredients’: ', '.join(record[‘features’]),
‘Price_Forecast’: record[‘predicted_price’],
‘Performance_Forecast’: record[‘predicted_win’],
‘Closest_Competitors’: ', '.join(record[‘closest_competitors’])
})
df_download = pd.DataFrame(records)
# Convert DataFrame to a simple string representation for .txt
txt_string = df_download.to_string(index=False)
# Return a dictionary with the content and filename for download
return dict(content=txt_string, filename="candy_empire_record.txt")
— NEW CALLBACK: Reset button functionality —
@app.callback(
[Output(“game-state-store”, “data”, allow_duplicate=True),
Output(“history-store”, “data”, allow_duplicate=True)],
Input(“reset-button”, “n_clicks”),
prevent_initial_call=True
)
def reset_game(n_clicks):
# Reset the stores to their initial state
return {‘successful_launches’: 0, ‘total_launches’: 0},
def create_market_map(new_candy_data, existing_tsne1, existing_tsne2):
“”“Creates the main t-SNE graph with a new candy.”“”
fig = go.Figure()
# Show all existing candies in the background
fig.add_trace(go.Scatter(
x=existing_tsne1,
y=existing_tsne2,
mode='markers',
name='Competitor Candies',
marker=dict(color='rgba(93, 78, 117, 0.7)', size=12,
line=dict(width=2, color='#AEA79F')),
hovertemplate='<b>%{text}</b><br>Status: %{customdata[0]}<br>Win Rate: %{customdata[1]:.1f}%<br>Price Level: %{customdata[2]:.1f}%<extra></extra>',
text=df['competitorname'],
customdata=np.stack((df['win_level'], df['winpercent'], df['pricepercent'] * 100), axis=-1)
))
# Highlight user's new candy if one has been created
if new_candy_data:
fig.add_trace(go.Scatter(
x=[new_candy_data['TSNE1']],
y=[new_candy_data['TSNE2']],
mode='markers',
name='Your Candy Empire',
marker=dict(
color='#DD4814',
size=25,
line=dict(width=4, color='#AEA79F'),
symbol='star'
),
hovertemplate='<b>🏆 YOUR CANDY EMPIRE</b><br>Position X: %{x:.2f}<br>Position Y: %{y:.2f}<extra></extra>'
))
# Clean map appearance
fig.update_layout(
title={
'text': "🌍 Market Battle Arena - Dominate Your Territory!",
'x': 0.5,
'font': {'size': 18, 'color': '#5D4E75'}
},
xaxis_title="",
yaxis_title="",
hovermode='closest',
showlegend=True,
legend=dict(
font=dict(color='#2c3e50'),
bgcolor='rgba(255, 255, 255, 0.9)'
),
xaxis_visible=False,
yaxis_visible=False,
template="plotly_white",
plot_bgcolor='rgba(252, 247, 245, 0.8)',
paper_bgcolor='#FCF7F5'
)
return fig
server = app.server