I had a simple approach and really wanted to get a Dash app running. Simple bars, line and pie charts slicing the data based of LLM recommendations on what it thought would be different interesting illustrations
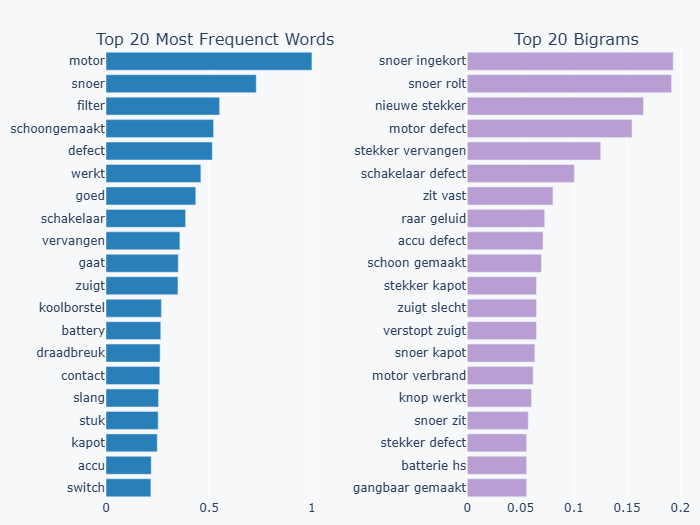
I struggled with the vacuum errors as some of the problems were descriptive and I had to import and attempt a couple libraries to solve the keyword search in the problem, didnt help that some were even in different languages lol.
example:
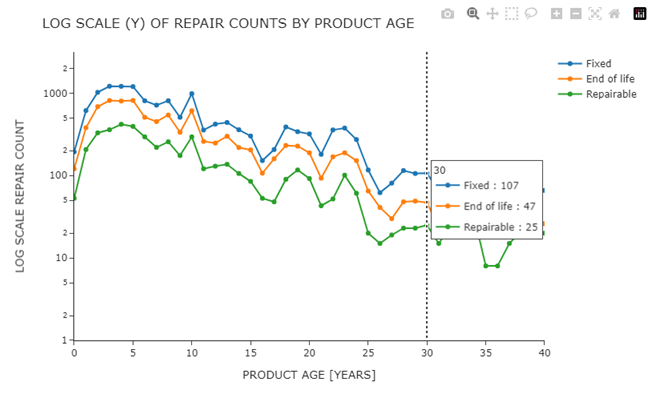
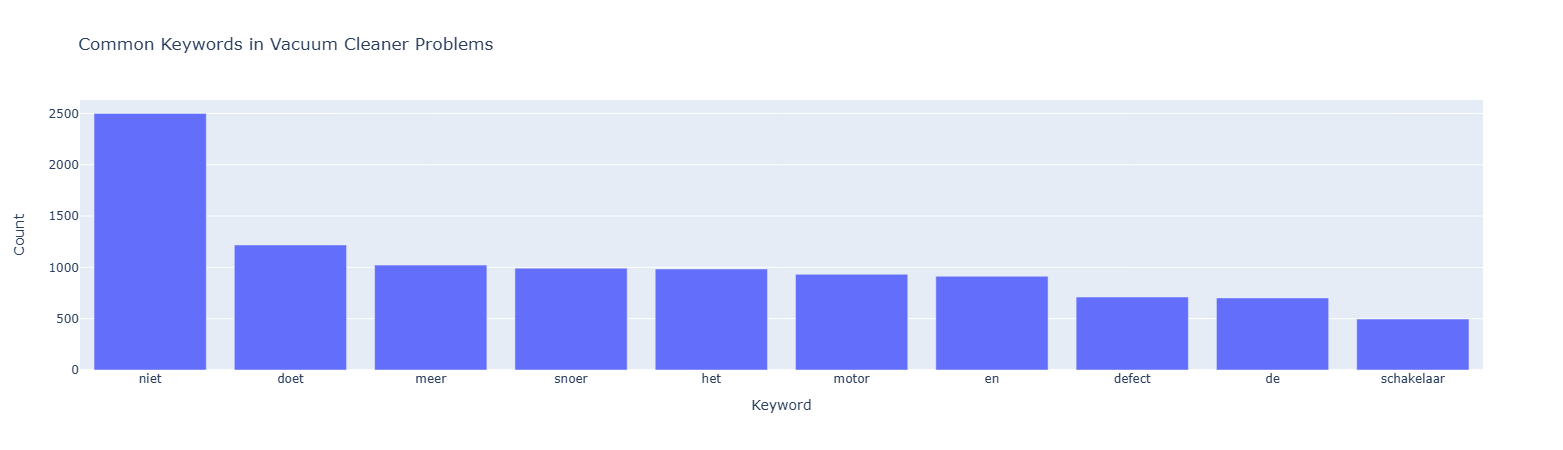
Common Faults in Specific Products (e.g., Vacuum Cleaners)
import dash
from dash import dcc, html
import plotly.express as px
import plotly.graph_objects as go
from dash.dependencies import Input, Output
import pandas as pd
from collections import Counter
import re
df = pd.read_csv("https://raw.githubusercontent.com/plotly/Figure-Friday/refs/heads/main/2024/week-43/OpenRepair_Data_RepairCafeInt_202407.csv", low_memory=False)
# Define a basic set of common stopwords
stop_words = set([
"i", "me", "my", "myself", "we", "our", "ours", "ourselves", "you", "your", "yours", "yourself", "yourselves",
"he", "him", "his", "himself", "she", "her", "hers", "herself", "it", "its", "itself", "they", "them", "their",
"theirs", "themselves", "what", "which", "who", "whom", "this", "that", "these", "those", "am", "is", "are", "was",
"were", "be", "been", "being", "have", "has", "had", "having", "do", "does", "did", "doing", "a", "an", "the", "and",
"but", "if", "or", "because", "as", "until", "while", "of", "at", "by", "for", "with", "about", "against", "between",
"into", "through", "during", "before", "after", "above", "below", "to", "from", "up", "down", "in", "out", "on", "off",
"over", "under", "again", "further", "then", "once", "here", "there", "when", "where", "why", "how", "all", "any",
"both", "each", "few", "more", "most", "other", "some", "such", "no", "nor", "not", "only", "own", "same", "so", "than",
"too", "very", "s", "t", "can", "will", "just", "don", "should", "now"
])
# Initialize the Dash app
app = dash.Dash(__name__)
# Layout
app.layout = html.Div([
html.H1("Repair Event Data Analysis"),
html.Div([
html.H2("Top 5 Product Categories Seen at Events"),
dcc.Graph(id='top-5-product-categories')
]),
html.Div([
html.H2("Barriers to Repair"),
dcc.Graph(id='barriers-to-repair')
]),
html.Div([
html.H2("Average Age of Products at Repair Events"),
dcc.Graph(id='average-age-products')
]),
html.Div([
html.H2("Repair Attempts Over Time"),
dcc.Graph(id='repair-attempts-over-time')
]),
html.Div([
html.H2("Repair Success Rate Distribution"),
dcc.Graph(id='repair-success-rate')
]),
html.Div([
html.H2("Common Faults in Specific Products (e.g., Vacuum Cleaners)"),
dcc.Graph(id='common-faults-products')
])
])
@app.callback(
Output('top-5-product-categories', 'figure'),
Input('top-5-product-categories', 'id')
)
def update_top5_product_categories_chart(_):
top_categories = df['product_category'].value_counts().nlargest(5)
fig = px.pie(values=top_categories.values, names=top_categories.index,
title="Top 5 Product Categories Seen at Events")
return fig
@app.callback(
Output('barriers-to-repair', 'figure'),
Input('barriers-to-repair', 'id')
)
def update_barriers_to_repair_chart(_):
try:
# Convert to DataFrame and ensure proper columns
barriers = df['repair_barrier_if_end_of_life'].fillna("No Barrier").value_counts().reset_index()
barriers.columns = ["Barrier", "Count"]
# Create bar chart
fig = px.bar(barriers, x="Barrier", y="Count",
title="Barriers to Repair", labels={"Barrier": "Barrier", "Count": "Count"})
except Exception as e:
# Create an empty figure with an error message if something goes wrong
fig = go.Figure()
fig.add_annotation(
text=f"Error generating chart: {str(e)}",
xref="paper", yref="paper",
x=0.5, y=0.5, showarrow=False,
font=dict(size=20)
)
return fig
@app.callback(
Output('average-age-products', 'figure'),
Input('average-age-products', 'id')
)
def update_average_age_products_chart(_):
# Ensure 'product_age' is numeric
df['product_age'] = pd.to_numeric(df['product_age'], errors='coerce')
# Group by product category, calculate mean, reset index, and get top 10
avg_age = df.groupby('product_category', as_index=False)['product_age'].mean().dropna().nlargest(10, 'product_age')
# Check the structure of avg_age for debugging
print(avg_age.head()) # This will output to the console for inspection
# Explicitly cast 'product_category' to string and 'product_age' to float for Plotly
avg_age['product_category'] = avg_age['product_category'].astype(str)
avg_age['product_age'] = avg_age['product_age'].astype(float)
# Create the bar chart
fig = px.bar(avg_age, x='product_category', y='product_age',
title="Average Age of Products at Events",
labels={"product_category": "Product Category", "product_age": "Average Age"})
return fig
@app.callback(
Output('repair-attempts-over-time', 'figure'),
Input('repair-attempts-over-time', 'id')
)
def update_repair_attempts_over_time_chart(_):
df['event_year'] = pd.to_datetime(df['event_date'], errors='coerce').dt.year
repair_attempts = df['event_year'].value_counts().sort_index()
fig = px.line(repair_attempts, x=repair_attempts.index, y=repair_attempts.values,
title="Repair Attempts Over Time", labels={"x": "Year", "y": "Number of Repair Attempts"})
return fig
@app.callback(
Output('repair-success-rate', 'figure'),
Input('repair-success-rate', 'id')
)
def update_repair_success_rate_chart(_):
success_rate = df['repair_status'].value_counts()
fig = px.pie(success_rate, values=success_rate.values, names=success_rate.index,
hole=0.3, title="Repair Success Rate Distribution")
return fig
@app.callback(
Output('common-faults-products', 'figure'),
Input('common-faults-products', 'id')
)
def update_common_faults_products_chart(_):
vacuum_problems = df[df['product_category'] == 'Vacuum']['problem'].dropna()
if vacuum_problems.empty:
fig = go.Figure()
fig.add_annotation(
text="No data available for common faults in Vacuum Cleaners",
xref="paper", yref="paper",
x=0.5, y=0.5, showarrow=False,
font=dict(size=20)
)
else:
all_words = []
for description in vacuum_problems:
words = re.findall(r'\b\w+\b', description.lower())
filtered_words = [word for word in words if word not in stop_words and len(word) > 1]
all_words.extend(filtered_words)
word_counts = Counter(all_words).most_common(10)
keywords, counts = zip(*word_counts)
fig = px.bar(x=keywords, y=counts, title="Common Keywords in Vacuum Cleaner Problems",
labels={"x": "Keyword", "y": "Count"})
return fig
if __name__ == '__main__':
app.run_server(debug=True)