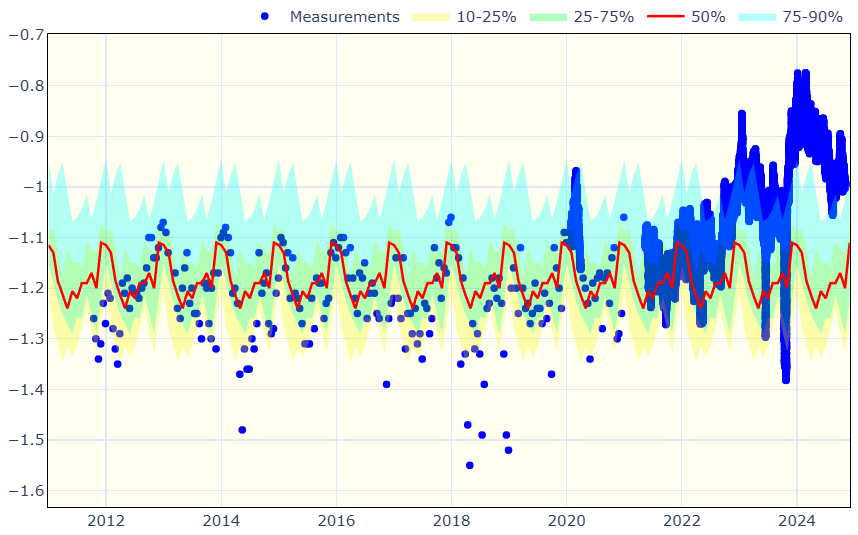
Hi,
I’ve got an issue with the density of markers. When they are spread apart, using markers seems to make more sense than a line, but as the frequency of measurements increases, the markers cluster up and they are very hard to distinguish from one another - which is fine, but looks pretty bad:
Hello,
When markers are densely packed, they can become indistinguishable and visually cluttered. Consider using a line to represent the data trend as the frequency of measurements increases. This can enhance clarity and improve the overall appearance of your visualizations. ringsizechart com
Hi @avimuni … I will try with this two parameters in the plot, 1) scatter_opacity and 2) update_layout_scattermode. I haven’t replicated the plot but seeing your picture I guess It would be easy for you to try it. I use opacity parameter and this is how it looks… I’ll hope be useful!
Hey JuanG, thanks for the response.
To my understanding, scattermode only works on points that share the same x/y values, so grouping them together would work if they had similar values, but what we’re seeing in your plot is in fact just lowered opacity taking place
What I would be interested in is 100% opacity for data points that are ‘alone’ and, for example 30% opacity for points that are clustered.
OK. Sorry if I’m wrong, but what if you create some new column (label) based on some kind of cluster with minimal amount of points around. I don’t know if you have some ML knowledge (I suppose you do…) but exploring some clustering algorithm you might classify your points with some label and plot only the labels you’re interested in. DBScan Cluster Demo of DBSCAN clustering algorithm