Hi all,
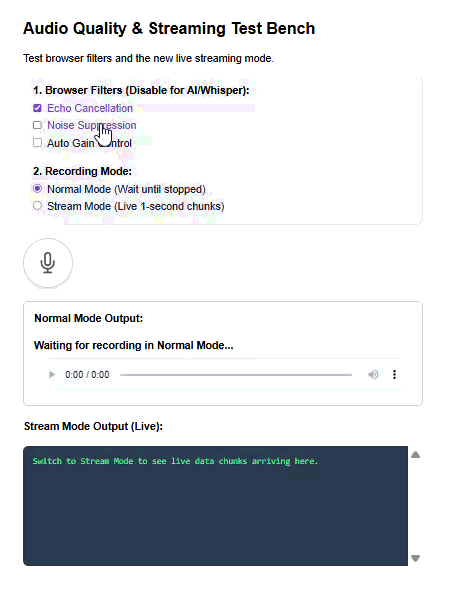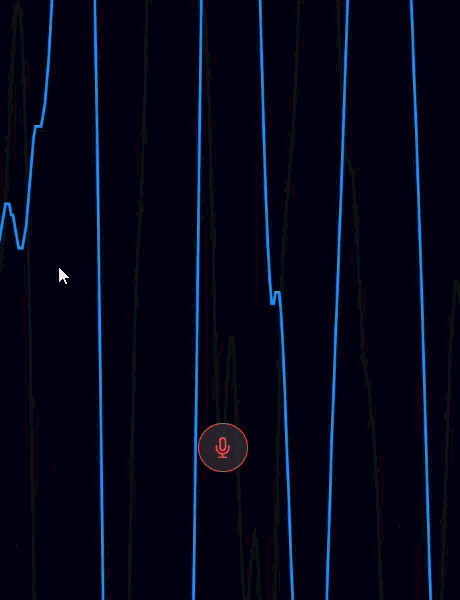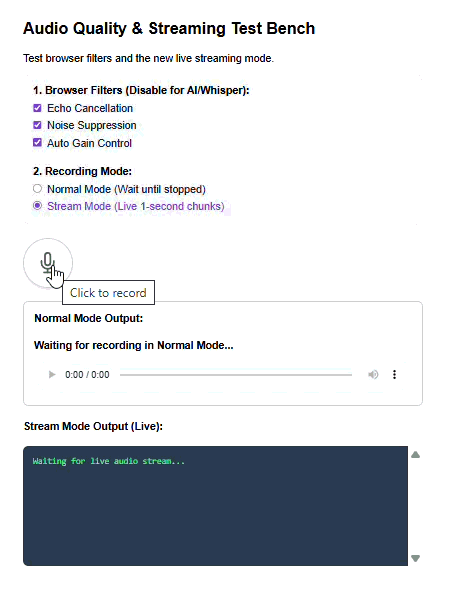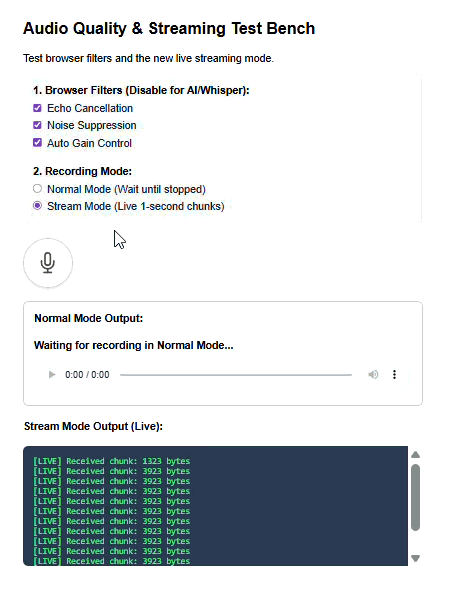
I wanted so something that I created for work purposes. I had a case where I was developing an agent chat application and I wanted have Speech-to-Text feature enabled with Whisper model. The thing is that Whisper might sometimes translate non-English speech to English due to audio quality. I made this component that enabled filtering echo, noise and the corrections that some browser might introduce so that the audio is as raw as possible.
Here is the link to Pypi
Here’s a demo view