fisbar
March 14, 2021, 5:50pm
1
I am trying to plot with plotly.express .line or plotly.graph_objects .Scatter with mode = ‘lines’ with the data that varies x value from 10E-15 to 10E+7 and y value from 10E-2 to 10E+6.
For both cases, the plot shows something like a step function in the lower range, especially under 10E-9 on the x-axis as shown in the figures, regardless of Log or Linear. When I plot this data with Gnuplot or Excel, the line looks very smooth.
I tried line_shape, line_smoothing, line_simplify options, but in none of the cases, the plot never changed. Is there any idea to make this plot completely smooth?
NickL
March 15, 2021, 1:04am
2
Hi @fisbar ,
Have you tried plotly.express.scatter instead of line plot?
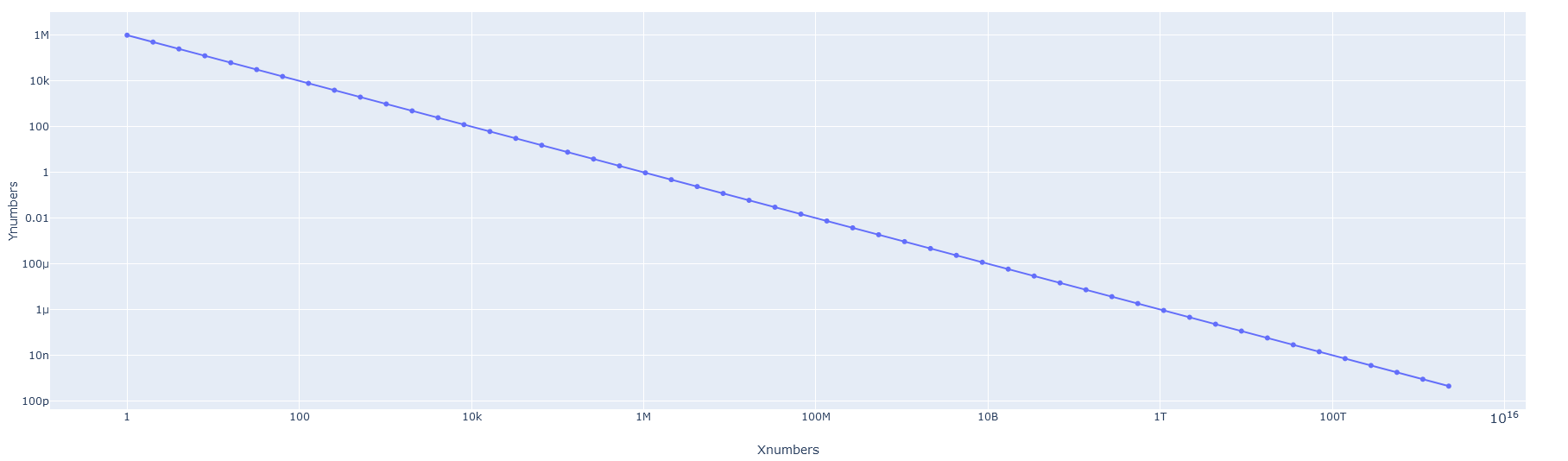
fig = px.scatter(data_frame=df, x=“Xnumbers”, y=“Ynumbers”, log_x=True, log_y=True)
Seems to work on my end! Here is a log-log plot with markers and lines for illustration.Log-Log Scatter with markers and lines|690x202
NickL
March 15, 2021, 1:33am
3
Here is a plot spanning more logs. Not recreating your issue in scatter plot (module versions: plotly==4.0.0).
fisbar
March 15, 2021, 10:36am
4
Hi NickL, thank you very much for your idea. I tried px.scatter and update(mode=‘lines’) but it also doesn’t work for my data below x=E-9. The point is that it is no problem above x=E-9.
Your idea made me realized that plotly plots the data below x=10E-9 very wired way. It doesn’t plot the data at the exact [X-Y] position, instead, it plots the data at every one step i.e., 1.0E-11, 2.0E-11, 3.0E-11, …9.0E-11!
I wonder if there are any options to read small numerical numbers. I really appreciate any help.
Following is the table I use for the plot here.
I pasted your data into a CSV and loaded it up like this:
import pandas as pd
df = pd.read_csv("~/Downloads/xy.csv")
import plotly.express as px
px.scatter(df, x="X", y="Y", log_x=True, log_y=True)
and got the following output, as expected:
… it seems like somehow the data you’ve read in is being clipped at some fixed precision or something?
fisbar
March 15, 2021, 3:03pm
6
Hi nicolaskruchten! Thanks for your check and comment. OK, I confirmed that too. Actually, the data contains more than 60,000 lines from x = 10E+2 down to x = 10E-11. I cannot share the data, but maybe that would be the reason…? I will try to skip some data points.
fisbar
March 15, 2021, 4:04pm
7
Yes, thanks for your hint, nicolaskruchten!
I figure out the reason. I convert the DataFrame into JSON format by df.to_json() and reconstruct DataFrame by pd.read_json(), because I need to share the DataFrame between some Dash callbacks. While to do so, the data type for X-axis has been changed.
Before:
After:
So my problem was definitely NOT Plotly’s problem. I will store/reconstruct DataFrame with the precisely specify data type.
Thanks for all your help!!!
added:double_precisio n






{kind=link}