Thanks for providing such a powerful tool!
I have a data frame of size 7486 rows x 960 columns. I am plotting the data with facet rows of 8 and columns of 2. Each plot has 3 categories and each category a group of 20 time series. Thus, each of the 16 contains 60 time series. I am plotting the data frame with plotly express lines, see snippet below. As renderer, I am using WebGL.
My impression is that plotly express line is rather slow. It uses a couple of minutes. Is this to be expected for this amount of data? Once it is rendered, the figures are responsive, though.
Thanks for any advice.
With respect to the large figure above, I have the problem to save the plots at static images, PNG format. If configured with kaleido engine, I get a crash, because of size. However, if I open the saved HTML thereof and save it from there as a static image, I get a PNG file without crash. Any advice on this?
fig.write_image(fig_file, format = img_format, engine = img_engine)
Have you tried to install orca? Perhaps that saves static images faster?
I don’t have experience with subplots, but ~ 10.000 data points are saved in PDF format in seconds. However, export using scattergl results in bad resolution which is why I omit the gl before final export.
Thank you for your advice. I made an attempt to use orca, but so far, it did not run out of the box. However, my primary issue is not the static image generation, but the rendering itself. The rendering itself take a lot of time - 15min or more - even before show or write_image.
Instead of plotly express line, I could use scatter, which seems to be much faster. However, with scatter, it is not possible to plot groups as with line_group. Thus, it results in one series with “jumping” lines and it is not possible to distinguish between individual runs anymore. How could line_group considered in scatter?
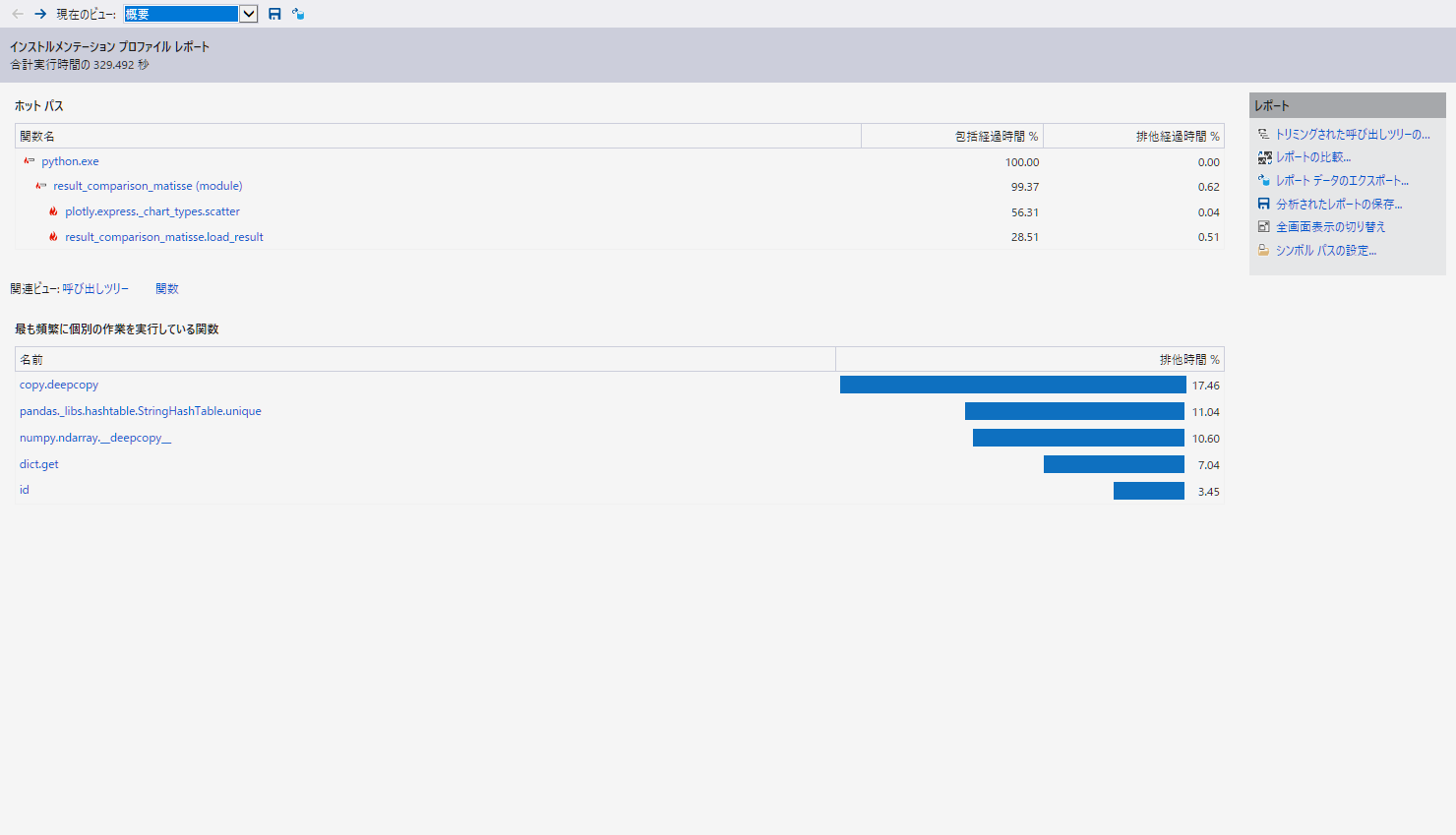
I did a profiling of line and scatter. For the same pandas data frame, line needs about 23min whereas scatter about 5min, see code snippets above. Scatter spends 56% of the time in the function plotly.express._chart_types.scatter, whereas line 79% in the function pandas.core.algorithms.unique. So, for some reason, line is doing a lot of access to the pandas data frame. Anybody an idea how to improve on that?
Still looking for advice to speed up plotly express line, if possible. - Might it help to rearrange the pandas data frame? Because of differing timestamps in each run, there are a lot of NaNs in the data frame. Might this slow down the plotting?
Would like to give this a bump and hopefully get some fresh eyes – I have a couple hundred parameterized functions and I’m trying to figure out the cleanest way to visualize them.
I made an np.linspace, and using line_group slows down the plotting by several minutes – the exact same dataframe takes but a few seconds to render without the line_group option set.
edit: seems as though my line_group column wasnt grouped how i thought it was, instead creating a grouping for every row. With the correct groupings it seems to be working fine.