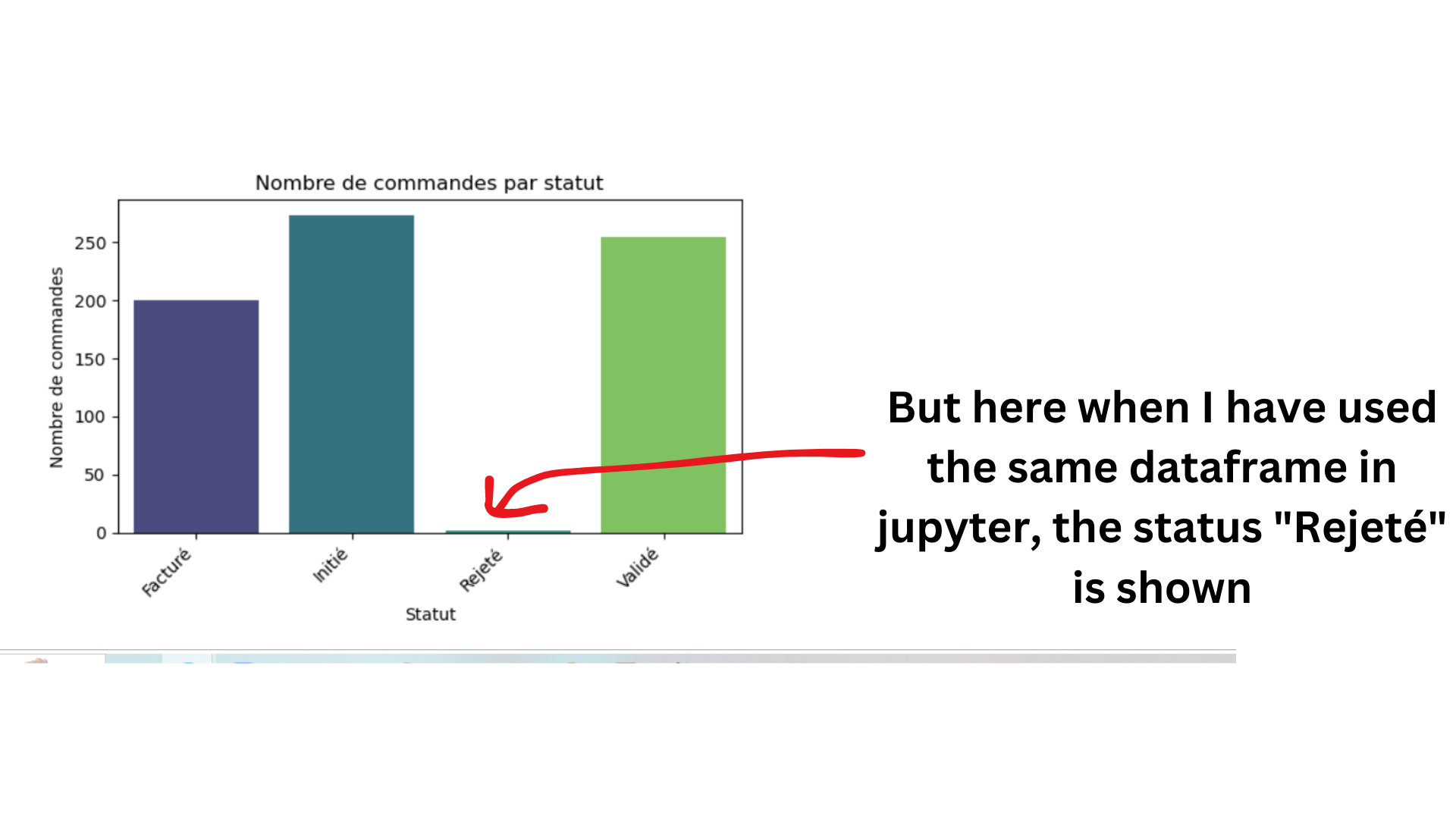
I’m encountering an issue where the “Rejected” status is not appearing in my Plotly bar chart even though it exists in the dataset. I have verified that the “Rejected” (Rejeté) status is present in the “Status” column of the DataFrame.
I have ensured that the data is not missing and that there are rows with the “Rejected” status in the DataFrame. Additionally, there are no formatting irregularities in the “Status” column. Despite these efforts, the “Rejected” status is not being shown in the bar chart.
I would appreciate any insights into why this issue might be occurring and how I can ensure that the “Rejected” status is properly displayed in the bar chart legend. Thank you in advance for your assistance.
here is the code of the function that I used to create a new data frame with new status (status that I want to visualize) and also, I share the code of the two bar charts and the screenshot of the figures.
def kpi_cda_page_2():
trimestre_df = data_ca()
# Filtrer les lignes avec des ID de commande d'achat uniques
trimestre_df_unique = trimestre_df.drop_duplicates(subset=['ID commande d\'achat'])
# Regrouper et agréger les données
grouped_df = trimestre_df_unique.groupby(['Nature Achat', 'Statut de la commande d\'achat']).agg({
'ID commande d\'achat': 'count',
'Valeur nette/limite commandée': 'sum'
}).reset_index()
grouped_df["Valeur nette/limite commandée"] = (grouped_df["Valeur nette/limite commandée"] / 1000).round(2)
grouped_df = grouped_df.rename(columns={"ID commande d'achat": "Nombre de commandes",
"Valeur nette/limite commandée": "Montant engagé",
"Statut de la commande d'achat": "Statut"})
# grouped_df
# Créer un DataFrame vide pour stocker les résultats
new_df = pd.DataFrame(columns=['Nature Achat', 'Nombre de commandes', 'Montant engagé', 'Statut'])
# Traiter le statut 'Facturé'
facture_df = grouped_df[grouped_df["Statut"].isin(["Terminé", "Document lié créé"])]
facture_result = facture_df.groupby(['Nature Achat', 'Statut']).agg({
'Nombre de commandes': 'sum',
'Montant engagé': 'sum'
}).reset_index()
facture_result = facture_result.groupby('Nature Achat').agg({
'Nombre de commandes': 'sum',
'Montant engagé': 'sum'
}).reset_index()
facture_result['Statut'] = 'Facturé'
new_df = pd.concat([new_df, facture_result], ignore_index=True)
# Traiter le statut "Engagé"
engage_df = grouped_df[grouped_df["Statut"].isin(["Terminé", "Document lié créé", "Envoyé"])]
engage_result = engage_df.groupby(['Nature Achat', 'Statut']).agg({
'Nombre de commandes': 'sum',
'Montant engagé': 'sum'
}).reset_index()
engage_result = engage_result.groupby('Nature Achat').agg({
'Nombre de commandes': 'sum',
'Montant engagé': 'sum'
}).reset_index()
engage_result['Statut'] = 'Engagé'
new_df = pd.concat([new_df, engage_result], ignore_index=True)
# Traiter le statut "Refusé"
refuse_df = grouped_df[grouped_df["Statut"].isin(["Refusé"])]
refuse_result = refuse_df.groupby(['Nature Achat', 'Statut']).agg({
'Nombre de commandes': 'sum',
'Montant engagé': 'sum'
}).reset_index()
refuse_result = refuse_result.groupby('Nature Achat').agg({
'Nombre de commandes': 'sum',
'Montant engagé': 'sum'
}).reset_index()
refuse_result['Statut'] = "Rejeté"
new_df = pd.concat([new_df, refuse_result], ignore_index=True)
# Traiter le statut "En cours d'approbation"
approba_df = grouped_df[grouped_df["Statut"].isin(["En cours d'approbation"])]
approba_result = approba_df.groupby(['Nature Achat', 'Statut']).agg({
'Nombre de commandes': 'sum',
'Montant engagé': 'sum'
}).reset_index()
approba_result = approba_result.groupby('Nature Achat').agg({
'Nombre de commandes': 'sum',
'Montant engagé': 'sum'
}).reset_index()
approba_result['Statut'] = "En cours d'approbation"
new_df = pd.concat([new_df, approba_result], ignore_index=True)
# Traiter le statut "Autres"
autre_df = grouped_df[
~grouped_df["Statut"].isin(["En cours d'approbation", "Terminé", "Document lié créé", "Envoyé"])]
autre_result = autre_df.groupby(['Nature Achat', 'Statut']).agg({
'Nombre de commandes': 'sum',
'Montant engagé': 'sum'
}).reset_index()
autre_result = autre_result.groupby('Nature Achat').agg({
'Nombre de commandes': 'sum',
'Montant engagé': 'sum'
}).reset_index()
autre_result['Statut'] = "Autre"
new_df = pd.concat([new_df, autre_result], ignore_index=True)
# Traiter le statut "Initié"
initie_df = grouped_df[~grouped_df["Statut"].isin(["En cours de préparation", "Refusé", "Interrompu"])]
initie_result = initie_df.groupby(['Nature Achat', 'Statut']).agg({
'Nombre de commandes': 'sum',
'Montant engagé': 'sum'
}).reset_index()
initie_result = initie_result.groupby('Nature Achat').agg({
'Nombre de commandes': 'sum',
'Montant engagé': 'sum'
}).reset_index()
initie_result['Statut'] = "Initié"
new_df = pd.concat([new_df, initie_result], ignore_index=True)
# Traiter le statut "Validé"
valide_df = grouped_df[~grouped_df["Statut"].isin(["En cours de préparation", "Refusé", "En cours d'approbation"])]
valide_result = valide_df.groupby(['Nature Achat', 'Statut']).agg({
'Nombre de commandes': 'sum',
'Montant engagé': 'sum'
}).reset_index()
valide_result = valide_result.groupby('Nature Achat').agg({
'Nombre de commandes': 'sum',
'Montant engagé': 'sum'
}).reset_index()
valide_result['Statut'] = "Validé"
new_df = pd.concat([new_df, valide_result], ignore_index=True)
return new_df
new_df= kpi_cda_page_2()
# Calculons le nombre de commandes pour les statuts inclus
# Liste des statuts que nous souhaitons inclure dans le calcul
statuts_inclus = ["Initié", "Validé", "Facturé", "Rejeté"]
# Créer un masque de filtrage basé sur les statuts inclus
mask = new_df['Statut'].isin(statuts_inclus)
# Appliquer le masque pour filtrer le DataFrame
filtered_df = new_df[mask]
# Calculer le nombre de commandes pour les statuts inclus
statut_counts = filtered_df.groupby('Statut')['Nombre de commandes'].sum().reset_index()
# Create the bar chart using Plotly Express
bar_fig_1 = px.bar(statut_counts, x='Statut', y='Nombre de commandes')
# Mettre à jour la couleur des barres en #ed1b24
bar_fig_1.update_traces(marker_color='#ed1b24')
bar_fig_1.update_layout(
title='Nombre de CDAs par statut',
yaxis_title=None,
xaxis_title=None,
yaxis_tickfont=dict(size=6),
margin=dict(
l=10, # Increase the left margin
r=10, # Increase the right margin
b=2, # Increase the bottom margin
t=60, # Increase the top margin
),
height=300
)
# Create the bar chart using Plotly Express
bar_fig_2 = px.bar(
filtered_df,
x='Nature Achat',
y='Nombre de commandes',
color='Statut',
barmode='group', # Utilisation de 'group' pour afficher une barre par statut
category_orders={'Statut': ["Initié", "Validé", "Facturé", "Rejeté"]},
# Ordre des statuts dans la légende
labels={'Nombre de commandes': 'Nombre de commandes'}
)
bar_fig_2.update_layout(
title='Nombre de CDAs par statut et par nature',
yaxis_title=None,
xaxis_title=None,
yaxis_tickfont=dict(size=6),
legend=dict(
#orientation="h",
#yanchor="top",
#y=-0.2,
#xanchor="right",
#x=0.8,
title="",
),
margin=dict(
l=2,
r=20,
b=2,
t=30,
),
height=300
)