Hi,
Just wondering if anyone can help me with this please…
I have to show a histogram of a column of data.
The column has 4 unique values in it…
[nan ‘Home work’ ‘Home & Online’ ‘None’]
When I create a histogram of it:
goHistQ25 = go.Histogram(x=df['Q25'],
showlegend=False,
histnorm='percent',
marker_color='gold',
)
I get one that looks like this:
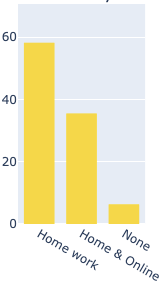
The overall percentages are showing that way because the histogram automatically ignores 'nan’s.
See how ‘Home work’ is nearly at 60% there?
But I need to include the NaN’s to show the percentages the way I need them… as in… I want to show the bar heights in relation to the people who chose the NA option.
So I am replacing the nan values with ‘NA’ in the dataframe just to illustrate here…
df = df.replace(np.nan, 'NA')
And you can see how it changes the heights of the first three bars… bringing ‘Home work’ closer to 40%
VS 
Which makes more sense in the context of the overall, including people for whom NA was a valid option to select in the survey… But now I have a 4th bar… the NA one…
So, I’m nearly there … just now I’d like to hide the ‘NA’ bar completely… while leaving the proportions the same as if it was in there… (if that makes any sense?? I want ‘Home work’ to stay at 40% even when NA is not displayed…
OR is there just some way to get Plotly to take the NaNs into account rather than ignore them?
Thanks