@empet
Thank you. I had a similar graph but I was trying to find a way to make rotated distribution plots. If it is not possible I will do histograms instead.
Is it possible to add data points to these bar graphs? To be precise, I have the following code:
# Creating instance of the figure
fig = go.Figure()
# Adding Male data to the figure
fig.add_trace(go.Histogram(y= df[(df['country']=='Norway') & (df['gender']=='M')]['age'],
marker=dict(color='plum'),
name = 'Male', orientation = 'h',
hoverinfo='skip'))
# Adding Female data to the figure
fig.add_trace(go.Histogram(y = df[(df['country']=='Norway') & (df['gender']=='F')]['age'],
x=-1 * np.ones(1000),
marker=dict(color='purple'),
histfunc="sum",
name = 'Female', orientation = 'h',
hoverinfo='skip',
))
fig.add_trace(go.Histogram(y=df[(df['country']=='Norway') & (df['gender']=='M')]['age'].sample(1,random_state=123),
orientation='h',marker_color="blue",
name='Current selection',
texttemplate=str(df[(df['country']=='Norway') & (df['gender']=='M')]['age'].sample(1,random_state=123).values[0]),
textfont_size=12
))
fig.add_trace(go.Histogram(y=df[(df['country']=='Norway') & (df['gender']=='F')]['age'].sample(1,random_state=321),
x=-1 * np.ones(1000),
histfunc="sum",
orientation='h',marker_color="red",
name='Current selection',
texttemplate=str(df[(df['country']=='Norway') & (df['gender']=='F')]['age'].sample(1,random_state=321).values[0]),
textfont_size=12
))
# Updating the layout for our graph
fig.update_layout(barmode='overlay',
yaxis=go.layout.YAxis(range=[0, 90], title='Age'),
xaxis=go.layout.XAxis(
tickvals=[-150, -100, -50, 0, 50, 100, 150],
ticktext=[150, 100, 50, 0, 50, 100, 150],
title='Number'))
fig.show()
This code is based on the following example: https://plotly.com/python/v3/population-pyramid-charts/
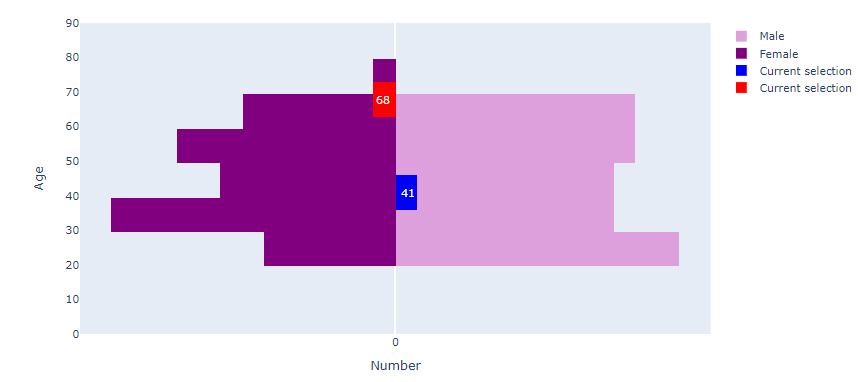
The graph output looks like this:
I want to show data points next to each histogram (similar to marginal=“rug” in px.histogram() ) and highlight ‘Current selection’ points in those data points. So, instead of those ugly looking highlighted bars that I have now, I want to show points.
You can replicate my data by running this code:
customers = [{'country':'Norway','age': random.randint(20,70),
'income': random.randint(50000,200000),'latitude': random.uniform(59,71),
'longitude': random.uniform(4,33), 'gender': np.random.choice(["M", "F"]),
'partner': np.random.choice(["Bank1", "Bank2", "bank3","Bank4"]),
'product': np.random.choice(["Product1", "Product2", "Product3"])} for i in range(100)] + \
[{'country':'Sweden','age': random.randint(20,70),
'income': random.randint(50000,200000),'latitude': random.uniform(55,69),
'longitude': random.uniform(11,24), 'gender': np.random.choice(["M", "F"]),
'partner': np.random.choice(["Bank1", "Bank2", "bank3","Bank4","Bank5","Bank6"]),
'product': np.random.choice(["Product1", "Product2", "Product3"])} for i in range(150)] + \
[{'country':'Denmark','age': random.randint(20,70),
'income': random.randint(50000,200000),'latitude': random.uniform(54,58),
'longitude': random.uniform(7,15), 'gender': np.random.choice(["M", "F"]),
'partner': np.random.choice(["Bank1","Bank2"]),
'product': np.random.choice(["Product1", "Product2"])} for i in range(60)] + \
[{'country':'Finland','age': random.randint(20,70),
'income': random.randint(50000,200000),'latitude': random.uniform(59,70),
'longitude': random.uniform(20,32), 'gender': np.random.choice(["M", "F"]),
'partner': np.random.choice(["Bank1", "Bank2", "bank3"]),
'product': np.random.choice(["Product1", "Product2"])} for i in range(40)]
df = pd.DataFrame(customers)