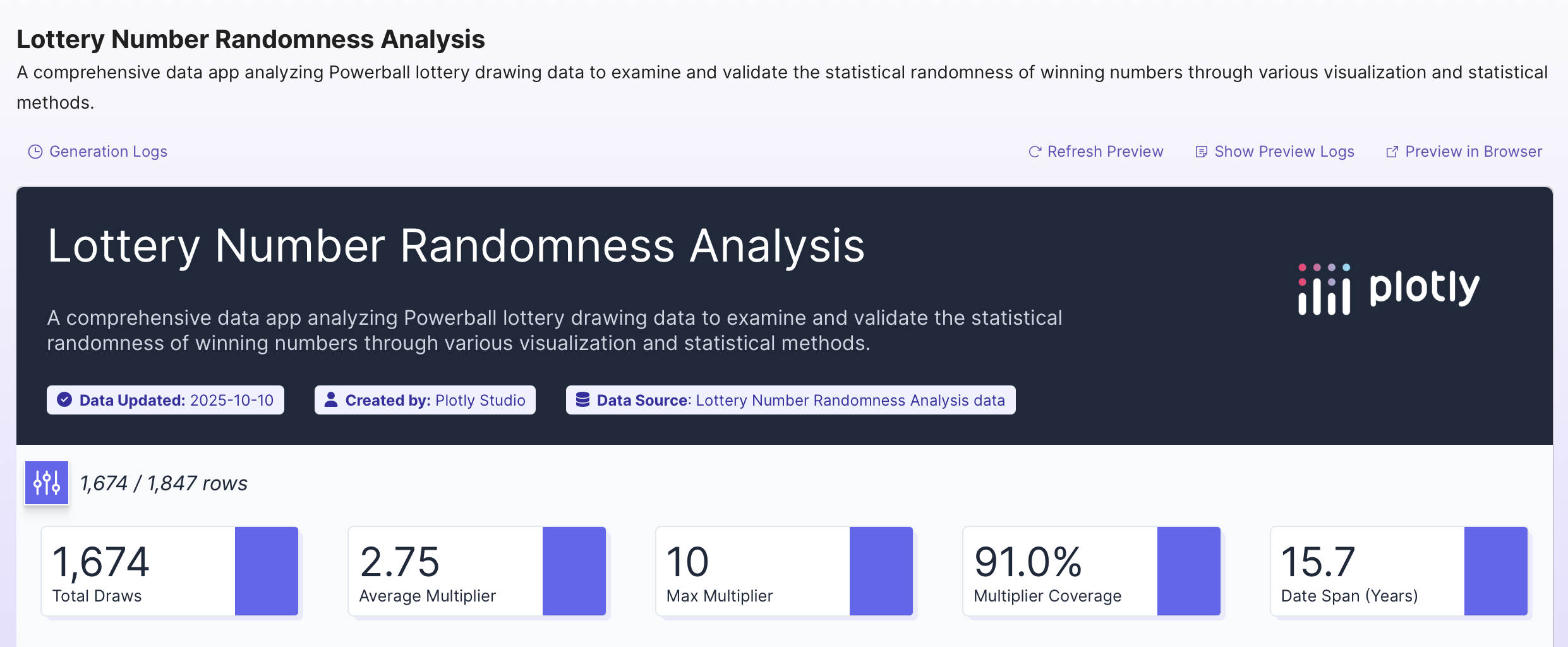
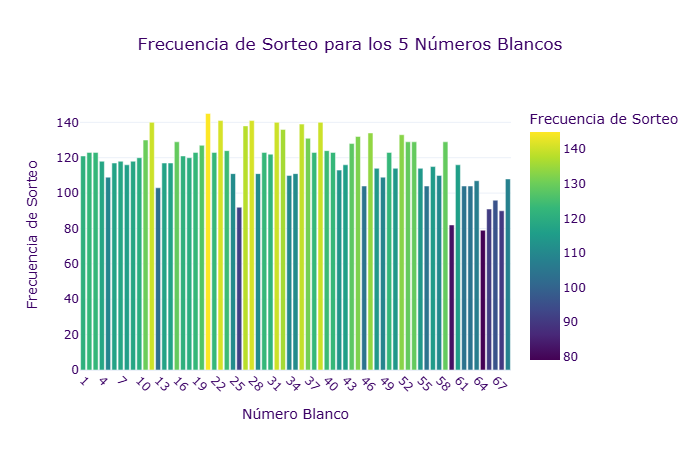
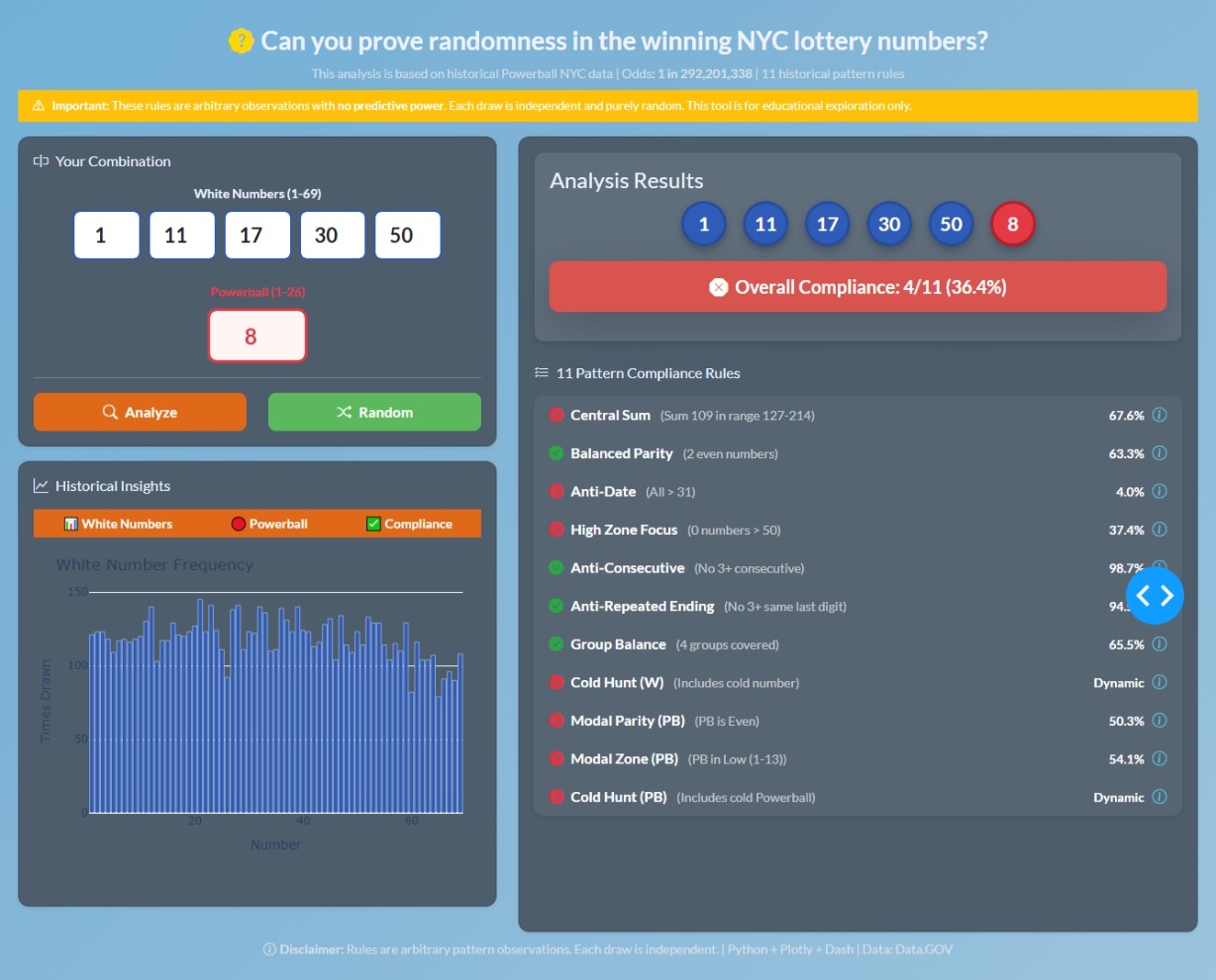
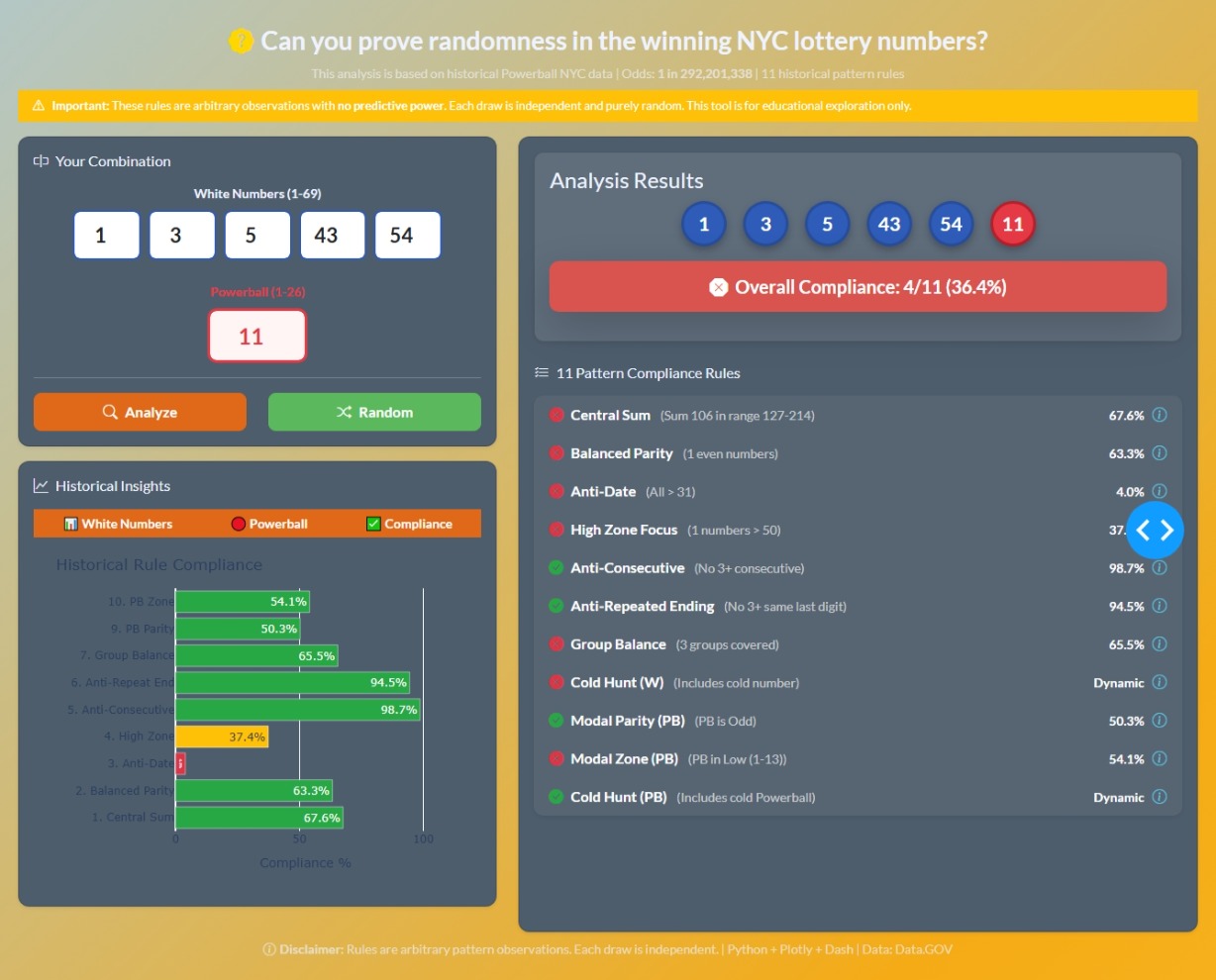
Here is a link to my dashboard for this week:
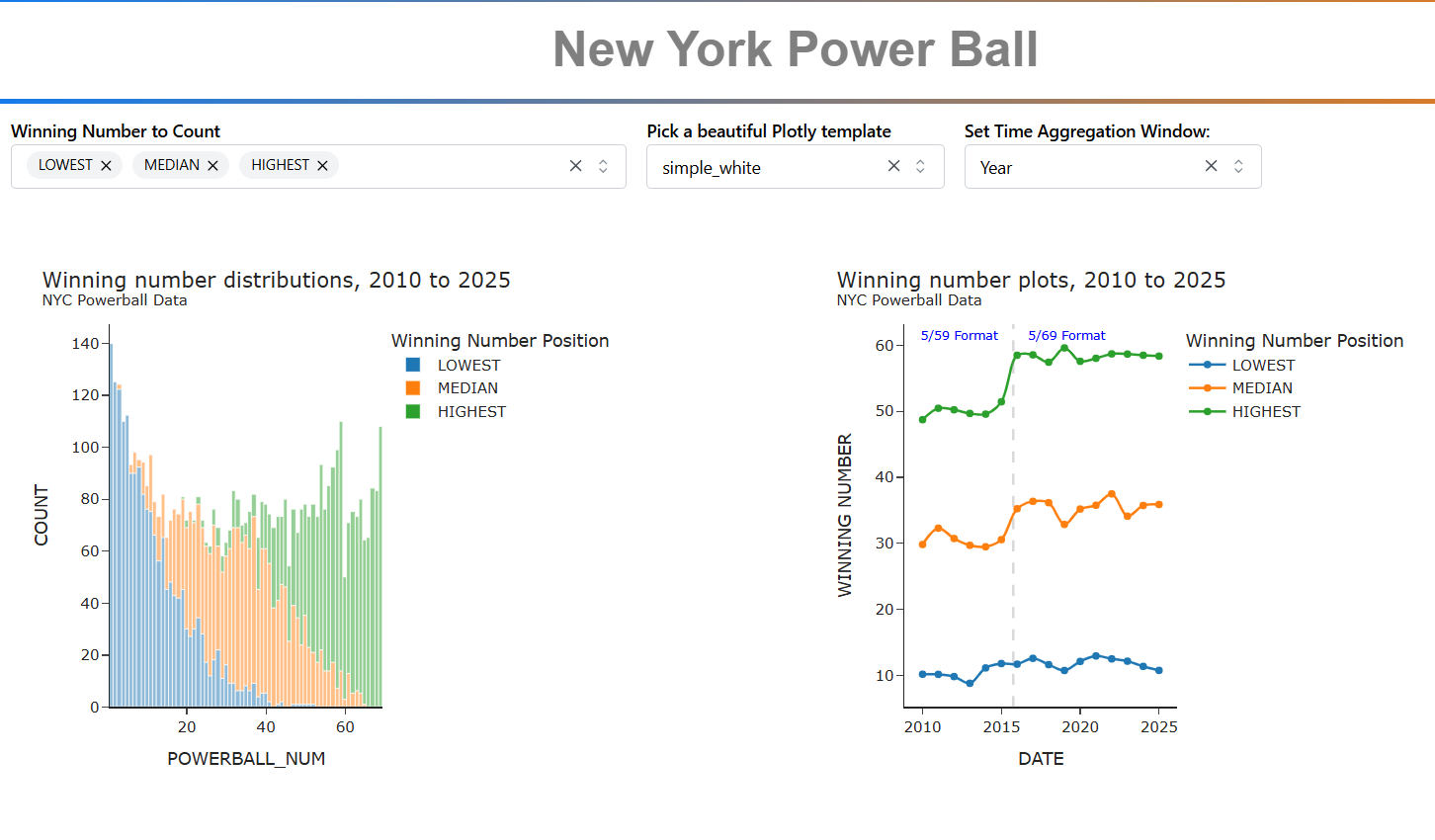
This analysis looks at the first five numbers of each Powerball drawing. The 6th ball or power ball is ignored.
The first five numbers range from 1 to 69 and are reported in ascending order. Prior to 2015, the numbers on each ball ranged from 1 to 59. The increase from 59 to 69 shows up in the timeline plot.
The range for each number is as follows:
- First number (LOWEST): 1 to 65
- Second number (SECOND_LOWEST): 2 to 66
- Third number (MEDIAN): 3 to 67
- Fourth number (SECOND HIGHEST): 4 to 68
- Fifth number (HIGHEST): 5 to 69
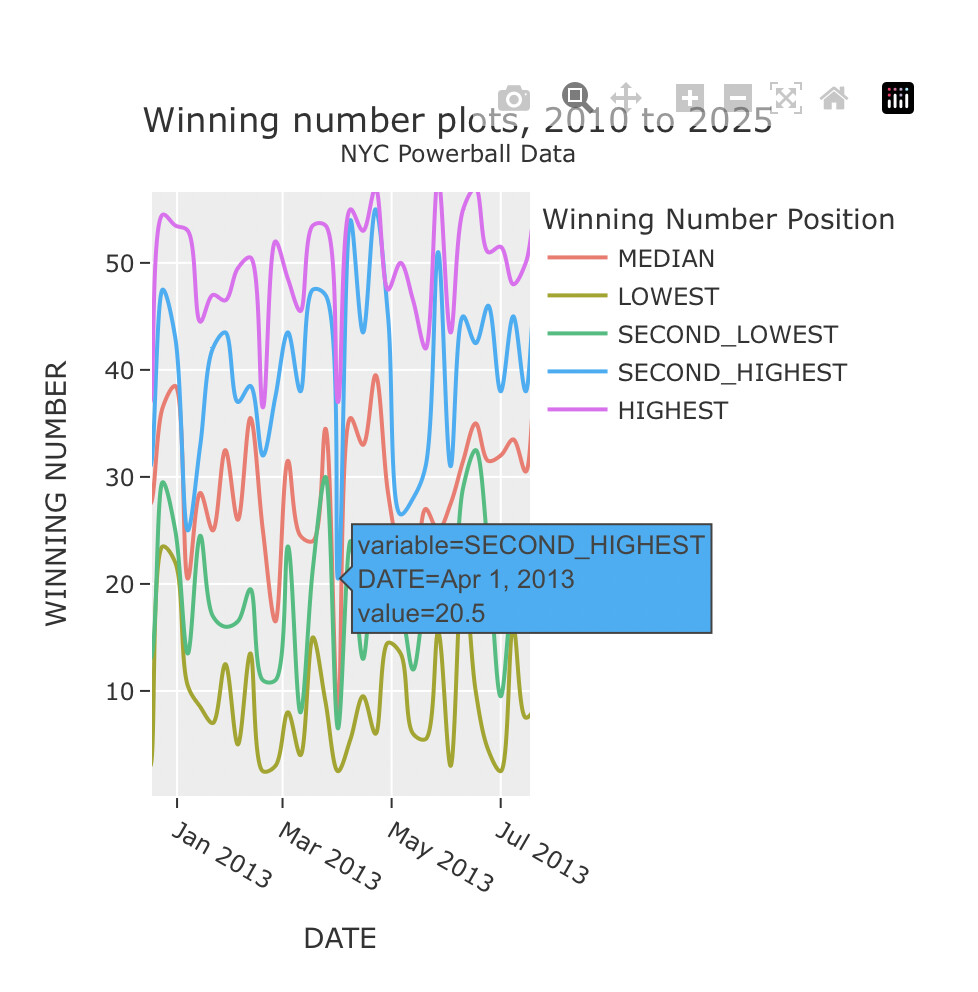
This histogram on the left shows the distribution of winning number positions. The timeline plots on the right shows the winning number positions from 2010 to 20215.
The pulldown menus select the visualization template, any winning number position (LOWEST, SECOND_LOWEST, MEDIAN, SECOND_HIGHEST or HIGHEST), and the time lime plot windows which uses polars dynamic group by to consolidate by week, month, year, or None.
Hope you enjoy it. Here is a screenshot:
Here is the code:
import polars as pl
import os
import plotly.express as px
import dash
from dash import Dash, dcc, html, Input, Output
import dash_mantine_components as dmc
dash._dash_renderer._set_react_version('18.2.0')
#----- GLOBALS -----------------------------------------------------------------
style_horizontal_thick_line = {'border': 'none', 'height': '4px',
'background': 'linear-gradient(to right, #007bff, #ff7b00)',
'margin': '10px,', 'fontsize': 32}
style_h2 = {'text-align': 'center', 'font-size': '40px',
'fontFamily': 'Arial','font-weight': 'bold', 'color': 'gray'}
pick_list = ['LOWEST', 'SECOND_LOWEST', 'MEDIAN', 'SECOND_HIGHEST', 'HIGHEST']
template_list = ['ggplot2', 'seaborn', 'simple_white', 'plotly','plotly_white',
'plotly_dark', 'presentation', 'xgridoff', 'ygridoff', 'gridon', 'none']
#----- LOAD AND CLEAN THE DATASET ----------------------------------------------
source_data = 'Lottery_Powerball_Winning_Numbers__Beginning_2010.csv'
if 'powerball.parquet' in os.listdir('.'):
print('reading data from parquet file')
df = pl.read_parquet('powerball.parquet')
else:
print('reading data from csv file')
df = (
pl.scan_csv(source_data)
.with_columns(
DATE = pl.col('Draw Date').str.to_date(format='%m/%d/%Y'),
SPLIT_NUMS = pl.col('Winning Numbers').str.split(' ')
)
.select(
pl.col('DATE'),
LOWEST = pl.col('SPLIT_NUMS')
.list.get(0, null_on_oob=True)
.str.strip_chars().cast(pl.UInt8),
SECOND_LOWEST = pl.col('SPLIT_NUMS')
.list.get(1, null_on_oob=True)
.str.strip_chars().cast(pl.UInt8),
MEDIAN = pl.col('SPLIT_NUMS')
.list.get(2, null_on_oob=True)
.str.strip_chars().cast(pl.UInt8),
SECOND_HIGHEST = pl.col('SPLIT_NUMS')
.list.get(3, null_on_oob=True)
.str.strip_chars().cast(pl.UInt8),
HIGHEST = pl.col('SPLIT_NUMS')
.list.get(4, null_on_oob=True)
.str.strip_chars().cast(pl.UInt8),
)
.collect()
.unpivot(
on=pick_list,
index='DATE',
variable_name='PICK',
value_name='POWERBALL_NUM'
)
.sort('DATE', descending=False)
)
df.write_parquet('powerball.parquet')
#----- DASH COMPONENTS------ ---------------------------------------------------
dmc_select_data = (
dmc.MultiSelect(
label='Winning Number to Count',
id='pick',
data= pick_list,
value=[pick_list[0], pick_list[2], pick_list[4]], # lowest, median & highest
searchable=False, # Enables search functionality
clearable=True, # Allows clearing the selection
size='sm',
),
)
dmc_select_template = (
dmc.Select(
label='Pick a beautiful Plotly template',
id='template',
data= template_list,
value=template_list[2],
searchable=False, # Enables search functionality
clearable=True, # Allows clearing the selection
size='sm',
),
)
dmc_select_aggregation = (
dmc.Select(
label='Set Time Aggregation Window:',
id='aggregation',
data= ['None', 'Week', 'Month', 'Year'],
value='Week',
searchable=False, # Enables search functionality
clearable=True, # Allows clearing the selection
size='sm',
),
)
def get_histogram(df, pick, my_template):
df_hist = df.filter(pl.col('PICK').is_in(pick))
fig = px.histogram(
df_hist,
x='POWERBALL_NUM',
color='PICK',
opacity=0.5,
template=my_template,
nbins=69
)
fig.update_layout(
showlegend=True,
title=dict(
text=(
'Winning number distributions, 2010 to 2025<br>' +
'<sup>NYC Powerball Data</sup>'
)
),
yaxis_title='COUNT',
legend_title_text='Winning Number Position',
)
return fig
def get_line_plot(df, pick, my_template, aggregation):
df_line = (
df
.filter(pl.col('PICK').is_in(pick))
.pivot(
'PICK',
index='DATE',
values='POWERBALL_NUM'
)
)
show_markers = False
if aggregation == 'Week':
df_line = df_line.group_by_dynamic(
'DATE', every='1w', closed='left', period='7d').agg(pl.col(pick).mean())
elif aggregation == 'Month':
df_line = df_line.group_by_dynamic(
'DATE', every='1mo', closed='left', period='1mo').agg(pl.col(pick).mean())
elif aggregation == 'Year':
df_line = df_line.group_by_dynamic(
'DATE', every='1y', closed='left', period='1y').agg(pl.col(pick).mean())
show_markers=True
fig = px.line(
df_line,
x='DATE',
y=pick,
template=my_template,
markers=show_markers,
line_shape='spline',
)
fig.update_layout(
showlegend=True,
title=dict(
text=(
'Winning number plots, 2010 to 2025<br>' +
'<sup>NYC Powerball Data</sup>'
)
),
yaxis_title='WINNING NUMBER',
legend_title_text='Winning Number Position',
)
fig.add_vline(
x='2015-10-04', # powerball format changed to 5/19 from 5/59
line_width=2,
line_dash='dash',
line_color='gray', #'green'
)
fig.add_annotation(
x='2015-01-01', y=1, xref='x', yref='paper',
font=dict(color='blue', size=10),
showarrow=False,
text='5/59 Format',
xanchor='right'
)
fig.add_annotation(
x='2016-07-01', y=1, xref='x', yref='paper',
font=dict(color='blue', size=10),
showarrow=False,
text='5/69 Format',
xanchor='left'
)
return fig
# #----- DASH APPLICATION STRUCTURE---------------------------------------------
app = Dash()
server = app.server
app.layout = dmc.MantineProvider([
html.Hr(style=style_horizontal_thick_line),
dmc.Text('New York Power Ball', ta='center', style=style_h2),
html.Hr(style=style_horizontal_thick_line),
dmc.Grid(children = [
dmc.GridCol(dmc_select_data, span=4, offset = 1),
dmc.GridCol(dmc_select_template, span=2, offset = 0),
dmc.GridCol(dmc_select_aggregation, span=2, offset = 0),
]),
dmc.Space(h=50),
dmc.Grid(children = [
dmc.GridCol(dcc.Graph(id='histogram'), span=4, offset=1),
dmc.GridCol(dcc.Graph(id='line_plot'), span=4, offset=1),
]),
])
@app.callback(
Output('histogram', 'figure'),
Output('line_plot', 'figure'),
Input('pick', 'value'),
Input('template', 'value'),
Input('aggregation', 'value')
)
def callback(pick, template, aggregation):
if not isinstance(pick, list): # if value is not a list, make it one
pick = [pick]
histogram = get_histogram(df, pick, template)
line_plot = get_line_plot(df, pick, template, aggregation)
return histogram, line_plot
if __name__ == '__main__':
app.run(debug=True)