Since I’m a simple guy, I like plain examples. I’m posting these bits here to help new people like me understand how to do this.
My use-case is a continuous color scale, with defined colors for minimum, midpoint and maximum values.
First I setup some public variables with the values I’m mapping from/to.
# Default min max for plotly color scale mapping
plotly_min = 0
plotly_max = 1
## Input data min/max values - 'a' is an arbitrary indicator input value
a_min = -1.0
a_max = 1.0
As you can see, plotly expects data from 0 to 1. Our input set is -1.0 to +1.0 - so we need to rescale it. Luckily I have a function that can do this easily:
## Takes number to convert, the old range min-max, the new range min-max - returns rescaled number
def rescaleRange(myNum, oldMin, oldMax):
# Since we're remapping to plotly range, no need for arbitrary input in function arguments
newMin = plotly_min
newMax = plotly_max
rescaledNum = ((newMax - newMin) * (myNum - oldMin) / (oldMax - oldMin)) + newMin
return rescaledNum
Okay, so how do we use this function to create our color list? Python allows you to call functions inside a list, which is handy:
redBlackGreen_scale = [[rescaleRange(-1.0, a_min, a_max), 'red'], [rescaleRange(0, a_min, a_max), 'black'], [rescaleRange(1.0, a_min, a_max), 'green']]
(Note that you can use RGB definitions as well instead of named colors by substituting ‘rgb(255, 0, 0)’ for ‘red’ – you can also use hex colors by using u’#‘, such as u’#ff0000’ for red. ‘u’ simply means use unicode encoding.)
There’s probably a more elegant way to do the above, but this is a simple example so I’ll leave it to be more verbose.
Okay smartguy, so how do you use this in a figure? Well, just as a basic example it would be something like:
fig = px.imshow(myInputData, text_auto=True, aspect="auto",
labels=dict(x="Indicator", y="Instrument", color="Level"),
x=['Fear/Greed', 'Volatility', 'Volume', 'Truckin'],
y=['BTCUSD '],
color_continuous_scale=redBlackGreen_scale
)
fig.update_coloraxes(cmin=-1.0, cmid=0, cmax=1.0) # Custom min/mid/max definitions
fig.update_xaxes(side="top")
There’s a lot here that can be changed, I’m still testing – but you see you assign your remapped color scale using ‘color_continuous_scale=’ in your figure. The min/mid/max also get defined here for your colorscale, otherwise it just assumes the default, which is automatic.
Here’s the figure output:
(Note, I haven’t done the per-column colorscales, just testing the custom scale applied to the entire heatmap for now.)
I’ve got more things to figure out, but I think I can use this heatmap example with subplots to do what I want without changing figure types:
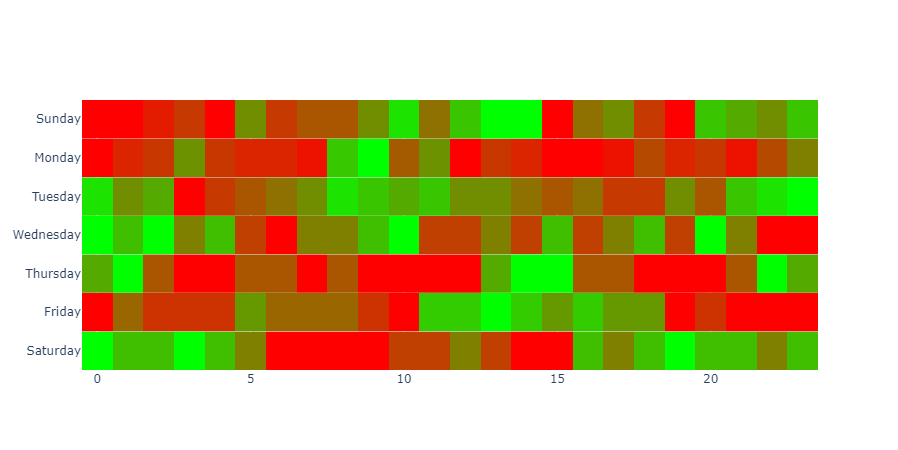
From stack overflow - Separate Heatmap Ranges In Plotly
Pasted here for reference:
# Below uses heatmap by row and then combines the plots
from plotly.subplots import make_subplots
import plotly.graph_objects as go
import pandas as pd
import calendar
# The test.csv file contents:
"""
0,0,1,2,0,5,2,3,3,5,8,4,7,9,9,0,4,5,2,0,7,6,5,7
1,3,4,9,4,3,3,2,12,15,6,9,1,4,3,1,1,2,5,3,4,2,5,8
9,6,7,1,3,4,5,6,9,8,7,8,6,6,5,4,5,3,3,6,4,8,9,10
8,7,8,6,7,5,4,6,6,7,8,5,5,6,5,7,5,6,7,5,8,6,4,4
3,4,2,1,1,2,2,1,2,1,1,1,1,3,4,4,2,2,1,1,1,2,4,3
3,5,4,4,4,6,5,5,5,4,3,7,7,8,7,6,7,6,6,3,4,3,3,3
5,4,4,5,4,3,1,1,1,1,2,2,3,2,1,1,4,3,4,5,4,4,3,4
"""
df = pd.read_csv('test0.csv', header=None)
# initialize subplots with vertical_spacing as 0 so the rows are right next to each other
fig = make_subplots(rows=7, cols=1, vertical_spacing=0)
# shift sunday to first position
days = list(calendar.day_name)
days = days[-1:] + days[:-1]
for index, row in df.iterrows():
row_list = row.tolist()
sub_fig = go.Heatmap(
x=list(range(0, 24)), # hours
y=[days[index]], # days of the week
z=[row_list], # data
colorscale=[
[0, '#FF0000'],
[1, '#00FF00']
],
showscale=False
)
# insert heatmap to subplot
fig.append_trace(sub_fig, index + 1, 1)
fig.show()
And finally, the resulting figure from the above example:
Anyway, thanks to the forum members and the book “The Book Of Dash” for getting me on the right track!!