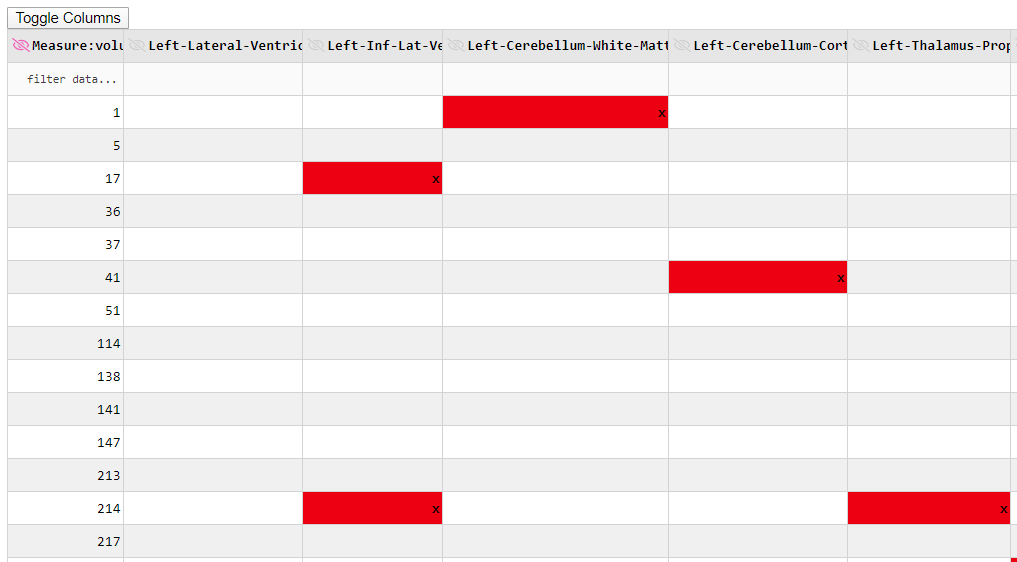
Hi there,
After I make columns hideable in the dash_table, the column width doesn’t adjust to text:
columns = [{'name': i,
'id': i,
'hideable': True
} for i in df.columns]
As you see, the column borders are curtailing my headers on top.
But if I remove the hideable, they are okay:
columns = [{'name': i,
'id': i,
} for i in df.columns]
Is this normal or do we have a fix for the former?
Hi @tbillah
can you share the code and data with us, so we can try this out on our computer?
Hi @adamschroeder,
The work is open source, please use: https://github.com/pnlbwh/freesurfer-analysis/blob/master/scripts/summary-table.py
For data, please download https://drive.google.com/open?id=1F-SySDKPOCEjc8GjkCkC02pitItdimta in the same folder of summary-table.py.
By the way, I think column width is calculated without considering ‘hide’, ‘sort’, or ‘delete’ icons. If I start adding one or more, the text gets trimmed as I have reported. You can try commenting out:
'hideable': True
filter_action='native',
sort_action='native',
and notice the change.
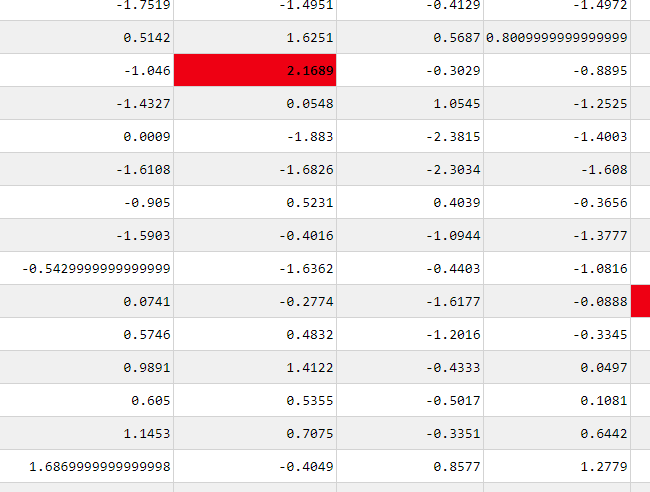
Also, can you check why there are repeating decimals in the dash_table?
I just updated my csv file and that has up to 4 decimal points only. But some of the cells miraculously seem to have obtained repeating decimals:
Hi @tbillah,
I sent you a private message regarding column width because I’m not sure if that’s possible with Dash DataTable.
Thank you for your sincere effort.
In other note, did either of you get a chance to look into the ‘miraculous’ repeating decimal?
that looks just like the way the data is being converted or read, an “issue” with floating point numbers. you can either preprocess the data to round the numbers before presentation or you can use the numeric formatting options in Typing and User Input Processing | Dash for Python Documentation | Plotly
Thanks @chriddyp, inclusion of type and format solved the problem:
columns = [{'name': i,
'id': i,
'hideable': True,
'type': 'numeric',
'format': Format(precision=4),
} for i in df.columns],

P.S. I wish I could let you know earlier … maxed out my replies yesterday 
1 Like
Hello again @chriddyp and @adamschroeder ,
I may have found a way around:
style_cell={'whiteSpace': 'pre-wrap'}
Including the above solved the problem:
1 Like
Wonderful news. This is very helpful. Thank you for sharing, @tbillah
1 Like
Actually, I realized that the way around I found is not consistent. Here is another data for which line breaks arbitrarily:

But at least I get to see the untrimmed header, some improvement over the original issue I originally reported.