It is the case. Thanks @chriddyp
I was using chrome to do the test. I was able to download the csv file up to 1328KB but fail with the csv file of size 1655KB. I guess it’s because the js link that the urllib generates introduce some overhead.
Tried firefox just now and it was able to download the csv file of size 7.8MB with no problem. Didn’t have chance to try larger data.
the URI specs are very useful, thanks!
That’s why, excellent, thanks!
Here is another approach that works for larger files:

Hm, I’m not sure why this isn’t working. You haven’t made any changes to the example that I posted above?
Which browser are you on?
Try inspecting the <a/> element that is rendered on the page, in particular its href property. The href property should be updated from the callback. Here’s what it looks like for me:
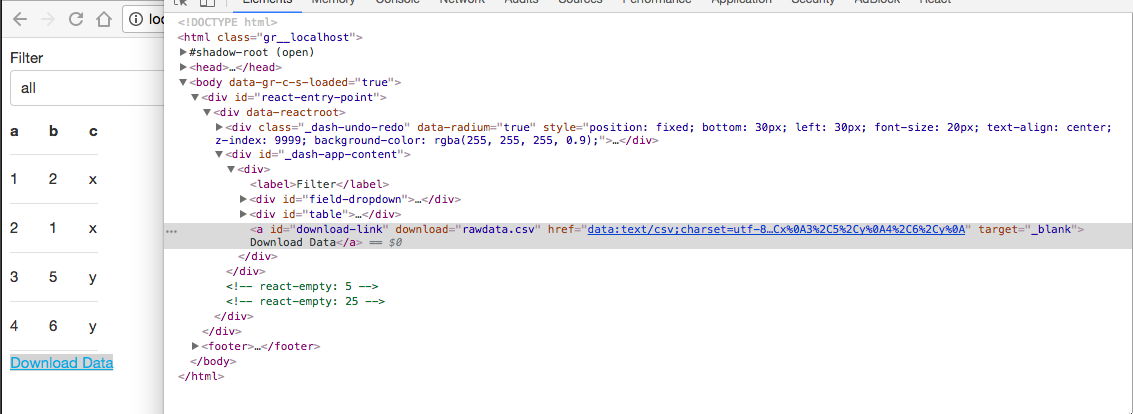

Weird, I don’t know why this isn’t uploading.
You could also check:
- Do data URIs work at all for you or are they for some reason blocked by your machine? I made this example for you to test: https://codepen.io/chriddyp/pen/aVammp
- Is the callback updating? You can add a print statement inside the callback to check if it’s being called.
- You can also inspect your network console to see if the HTTP request is responding correctly. Here is a screenshot of the request, it will be the second
_dash-udpate-componentrequest and the payload will have a JSON object with{"response": {"props": {"href": "data:text/csv;...."}}}
- Are there any errors in the console?


Hi juakali,
in addition to chris’’ notes:
Do you have the following statement in your code?:
app.config['supress_callback_exceptions']=True
When I had problems with callbacks that are not updating, I wasn’t able to debug, because of my own settings. Set to “False” to receive an error when trying to call a callback.
Kind regards
Stuart
Hi @Stuart_Kerkhof and @chriddyp,
Thanks for your help and the examples, much appreciated. I forgot to update my solution but in the end it was a very small thing - I’m using Python 3 and needed to replace urllib.quote with urllib.parse.quote
I noticed the data URI works in Chrome if you remove href="_blank".
2 questions:
1- can one download links save several files at once… say i want to split the table into two and save both halves as separate files?
2- can i change the path the file is getting saved to?
@chriddyp @carlottanegri Is it possible to change encoding? Excel will automatically open csv link, but encoding is incorrectly. I have to manually use txt to change encoding into ansi, and reopen with excel. I also tried to modify ‘utf-8’ to ‘ansi’. But it does not work… any suggestion?
I made two changes to the callback in @chriddyp’s example.
-
Use
urllib.parse.quoterather thanurllib.quote(Python3 compatibility) -
Add
%EF%BB%BFto the beginning of the CSV file, which is a Byte Order Mark (BOM) for UTF-8 encoded files. This ensures that programs like Excel will open the CSV file correctly without modifying special characters.
The final callback is:
@app.callback(dash.dependencies.Output('download-link', 'href'),
[dash.dependencies.Input('field-dropdown', 'value')])
def update_download_link(filter_value):
dff = filter_data(filter_value)
csv_string = dff.to_csv(index=False, encoding='utf-8')
csv_string = "data:text/csv;charset=utf-8,%EF%BB%BF" + urllib.parse.quote(csv_string)
return csv_stringYes! That did it. Tested it in Chrome and Firefox. Thanks to everybody for this.
@chriddyp, how can we do the same thing by creating the file with a unique name in the server and link that file to a download button or the html.A? For example, the link can be http://serverip/filename.xlsx.
I tried, but as I am developing in a local setting, I put the file in the current working directory. However, the html.A creates a link like "127.0.0.1:8050/file1.xlsx. I am not sure where to put that file so that I can link and download it.
Anybody know if its possible to do this with data that’s being pulled from a db to populate a table, specifically a MySQL db?
Thanks for sharing this technique - really useful. Can’t wait to fully implement it.
I tried using both @chriddyp’s example and @amarv your example but still faced the same errors ( downloaded csv returns html coode.
I had to make the following changes while using python 3.6:
s=StringIO()
csv_to_download=df.to_csv(s)
csv_string=“data:text/csv;charset=utf-8,%EF%BB%BF”+urllib.parse.quote(s.getvalue())
returncsv_string
Note: Following imports:
import urllib.parse
from import StringIO